
The Detection Engineering Process

This webcast was originally published on November 8, 2024.
In this video, Hayden Covington discusses the detection engineering process and how to apply the scientific method to improve the quality of detections. The discussion includes the steps involved in creating a high-quality detection, such as research, query building, backtesting, and continuous improvement. Hayden emphasizes the importance of structured processes, documentation, and the role of passion and enthusiasm in cybersecurity work.
- Detection engineering involves applying the scientific method to enhance the quality and consistency of detections.
- The process of creating a high-quality detection includes steps such as defining a detection story, conducting research, building a query, and continuous improvement.
- A structured detection engineering process can lead to better-defined scope, higher-quality detections, and improved overall security management.
Highlights

Understanding Detection Engineering Terminology and the Scientific Method
Clarifying detection engineering terminology like 'detection', 'alert', and 'ticket' to ensure audience understanding; discusses scientific method.

Structured Approach to Building PS Exec Plain Text Authentication Detection
Explore the structured process of building a PS Exec Plain Text authentication detection through a formalized detection story.
The Importance of Research and Documentation in Detection Processes
Begin with thorough research and documentation, refining insights from the initial detection story for effective analysis.

Importance of Backtesting: Preparing for Effective Detection Implementation
Before publishing detections, backtest queries against historical data to refine accuracy and document results for future reference.
Ensuring Accurate Detection by Using Real Data with Caution
Ensure detection accuracy by replaying real data, but beware of setup changes affecting static data reliability over time.

Efficient Alert Management in Detection Engineering
Streamline alerts by suppressing repetitive ones through host and username pairing, ensuring focused investigations without distractions.

Evolving Detection Engineering: Applying Scientific Methods to Alerts
Detection engineering involves evolving and adapting alerts through research and scientific methods, treating detections as evolving theories.

Balancing Automation and Human Oversight in Detection Engineering
AI can streamline detection engineering but still requires human oversight to ensure accuracy and reliability in security processes.
Black Hills: Passionate and Engaged SOC Analysts for Enhanced Security Solutions
Black Hills fosters a passionate SOC environment, offering enthusiastic analysts who excel technically and enjoy collaborative problem-solving.
Full Video
Transcript
Jason Blanchard
Hello, everybody, and welcome to today’s Black Hills Information Security webcast. My name is Jason Blanchard. I’m the content community director here at Black Hills. And if you ever need a Red Team threat hunt, active SOC, ANITSOC, or any other services we provide, you know where to find us.
But today we got– Hayden is going to talk to you about the things that Hayden wants to talk to you about. So the detection engineering process. So what happens is we reach out to each one of the people who work at, at Black Hills, the technical team, and say, would you like to give a webcast?
And a lot of times they’re like, I don’t know what to talk about. and so Hayden, I reached out and he’s like, oh, I have an idea. let me take some of the material from the class that I’m putting together, and I’m going to do that.
And so Hayden is taking material from a class that he’s designed for the Antisyphon training organization, and he’s going to today as part of a free, webcast. But Hayden is a part of our SOC.
Hayden, your life revolves around, like, detection engineering. Like, this is a thing that you do all the time, right?
Hayden Covington
Yes. Yeah, definitely. It’s, a lot of my time, especially as of late.
Jason Blanchard
Yeah. And Hayden came, on a webcast last year. It was so good not to raise expectations, not to, like, make Hayden want to, like, oh, my God, stop. but it was so good last year.
We were like, hey, you should put a class together. Like, you should come back. You should do this. And I hate that I should it all over him. but, Hayden rose to the occasion and created a, class, and he’s going to go ahead and give this webcast today.
So I’m going to head backstage. Hayden, if you need me at any time, I’ll pop back on. If you disappear for any reason, I’ll hop back on. but thank you so much for joining us. Please join us in Discord. If you haven’t checked in for Hackett yet, please do that.
we keep track of how many webcasts you attend. Once you hit 10, we send you a reward. And 20, 30, 40, and 50, we send you rewards. And we appreciate you being here. There’s a lot of places you could have been today, and you decided to come here, and we appreciate that.
All right, Hayden, it is all yours.
Hayden Covington
Awesome. Thank you. And so, as Jason said, a lot of this is pulled right from the course that I have. I will talk about that course some more later.
That’s at the very end. That way if you don’t want to hear about that, you only have to hear about the detection engineering which if you can’t tell, I’m kind of excited to talk about, but anyway, or to the slides, today talking about detection engineering and in my opinion how you should apply the scientific method to that process in order to get a better output.
But I’m already jumping ahead of myself so we’ll get to the first slide. who am I? Jason mentioned it a little bit. I work in the Black Hills SOC.
I’m a SOC analyst, detection engineer, security engineer, who knows? I do a lot of different things, but I do spend a fair bit of time doing detection engineering for Black Hills and for other companies.
As a person, I’m about as type A as you can get, which is hyper organized, very specific and set and not rigid but definitely very very specific and intentional kind of aligning with that some of my personal interests.
I’m a triathlete. I am obsessed with formula one. so those two things kind of very highly, linked together in terms of data, in terms of that, that sort of personality type.
The last website, the last webcast I gave was on SOC metrics. So that kind of you a general idea of what to expect from me.
So with that said, let’s jump into a couple key terms. I want to cover these first just to make sure that when I say things, you understand what I’m talking about. Detection engineering has a lot of different terms that people use.
A great example which isn’t on this slide is false positive. That can mean a ton of different things to many different people. And so I just want to kind of level set right here of when I say something and that way you understand exactly what it is I’m trying to get across with that word.
So detection or rule is going to be the search syntax, usually in your sim that is detecting the activity. So that is detection or rule alert is going to be the output of a detection and then a ticket is what ends up in your ticketing system.
And so generally what that looks like, at least what it looks like for Black Hills, is we have a detection that fires that detection creates an alert and then that alert based on different criteria will or will not end up in the ticketing system.
So just to level set that so that, where I’m coming from as I use these words fairly interchangeably, detection or rule I’ll use interchangeably.
But if I say alert, I mean alert, not necessarily ticket, but that said, and talk a little bit about the scientific method. so scientific method, science will generally follow a very static and rigorous method to come to a formalized conclusion.
And that process is going to be observation, research, hypothesis, experimentation, analysis, conclusions. And then you kind of repeat as you go, and I’m sure you probably remembered this from school, some of you, is that, this is a very specific method in how things go from being a observation to becoming a theory.
And so in terms of, the scientific method here, your sort of process kind of starts when you make an observation, you see something and you go, oh, okay, let’s look into that a bit more.
And as you research it, you might formalize a hypothesis. As you kind of go through that process, it goes from an observation to a hypothesis. And then you start experimenting.
You’re validating what it is that you think based on your hypothesis. And if I breezed over, a hypothesis is basically just a, just a simple way of saying, or a scientific way of saying what you think the case is.
So that’s your assertion about what you believe in this specific circumstance. And so your experiment, you test it, you check those results, you determine whether or not it aligns with your hypothesis.
If it does, that’s great. If it doesn’t, you revise that. And the ultimate goal of this process is to have your work turn into something that is a scientific theory.
So theories in the science world are basically, it is something that can be repeatedly tested and validated. atomic theory is a very good example of this, that everything is composed of atoms.
You can test that, and it has been tested for quite some time. and it is repeatable, you can validate it. but it didn’t always remain the same.
it did change over time as new things were discovered. what is the equivalent though to detection engineering for, the scientific process here?
So what is the equivalent to a theory? A, theory for detection engineering is going to be a high quality detection. Something that’s well researched, well documented.
it’s verifiable, reproducible, it’s continuously improved. it is a hypothesis that you’ve built on, you’ve theorized on, and you continually, repeatedly test this to make sure it is valid.
And so you’re probably thinking, what does this have to do with detection engineering? What’s the point of this webcast? Can we stop talking about school? That’s probably what you’re thinking, maybe, maybe not.
but I’m going to align that scientific process to the detection engineering process and kind of explain to you how you can do them sort of in the same way, and come to a better result, or at least a more consistent result in terms of high quality detections.
So the two processes kind of can align if you look at them in the right way. So you start with a detection story and I’ll cover each of these and we’ll actually walk through an example of what each of these looks like.
but you would start with a detection story. You have research based on that story. You build the query, you backtest the data, you build canaries documentations and then you onboard it.
And it doesn’t end there, you continuously improve it. Just like if it were a theory, continually validating and making sure that it holds up, your hypothesis for the detection engineering side of things could start with your research phase.
It doesn’t have to start with a detection story. You could be researching something and go, oh, this would make a great detection. but generally in a lot of cases it will have some sort of input which we will talk about kind of comparing these two side to side.
you have, they line up pretty well. So your observation, is, your detection story is your hypothesis or your research. Your query and your backtest are going to be your experiments.
Your canary is validating and confirming your hypothesis and your data also validating that it works. as part of your experiments documentation for detection engineering is going to kind of be your reporting.
And then as you onboard your detection and you improve it, that’s going to be your your theory. So I talked a little bit about it, but why does this matter?
So what’s the benefit of actually following a process? Like is it just going to add more time? It will add a little bit of time maybe to your detection engineering flow. but why should you care?
So there’s a couple reasons. the first is a better defined scope. So if you build detections in this way, you’ll have the scope defined from the start, at least more so than you might.
And it will allow you to better focus on the intended output of that detection. You’ll have an easier understanding of what you’re looking for. Because inherently built into this process there will be research, there will be documentation.
And so as you’re building things you’re going to have already researched what it is you’re looking for. You’re not going to miss any steps. So as you’re going through a framework, going through a process, it’s a lot easier to not have to worry about forgetting steps in between.
And then ultimately the goal is to have a higher overall quality for your detections. So as promised, going to apply this to a scenario.
We’re going to walk through each of those steps and basically build a detection. So this detection is going to be PS Exec Plain Text authentication.
So the first step being the detection story is where we’re going to start with this one. So detection story, it’s a way, it’s your input, it’s going to be your initial input.
In a lot of ways, we call it a detection story. To you it might just be a ticket that somebody puts into the detection engineering team. but this detection story should, be done in a structured way.
You should have a reason for this. Detection should have data sources. You have, some example volumes, some artifacts. you shouldn’t just have a ticket that says, hey, can you make a detection for PS Exec?
It needs to be more formula or more formalized. You need to have it, vetted. You need to be able to require certain things before you accept these. Otherwise you are going to, waste a lot of time guessing what the original person wanted, what the original requester wanted, or in some cases you’ll just make a detection that was entirely unnecessary.
some of these sources, like I mentioned, could come from your peers, could come from your management, but it also could come from, blogs, articles, customer requests. in the case of this one, came from a previous, attack.
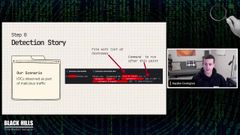
And so this specific detection, I’m showing you the command line log. Now this is an IOC observed as part of malicious traffic that we saw.
And so this is PS Exec, and it is, passing a list of hosts and then it is authenticating as a user with a password in plain text over the command line.
And then it is providing and copying malware to a, specific folder on each of those machines in that list of hosts. And so in this case for the detection story, somebody submitting this, their reason could just be, observed malicious IOC is or, malicious traffic.
Your source for this would probably be Windows. and then expected volume depends entirely on your environment. But in, a little bit of a spoiler alert, expected volume for us and the folks that we monitor is low.
and then artifacts is very important if you can have them. So linking to resources. so this would be the detection story, the next step, the first official step in this process, because I count that detection story as just an initial input, is going to be your research.
So research and document things that you find and try as you go, as you go through and you experiment with things, you try queries, you see what does and doesn’t work.
you should be documenting all the things that you find, all the reports, details. You can always remove them later if they’re not relevant to the final product in your notes.
But, I would really highly recommend that you write these things down in case you need them later. a good detection requires you to have a full understanding of what it is you’re looking for.
And this research should be based off of that initial detection story. you should be very careful of this scope. You can very easily find yourself branching out too far. Like you could go from, PS Exec plain text authentication to just looking for PS Exec or maybe PS Exec interacting with file shares and you all of a sudden find yourself working on something that’s actually like four different detects.
Or you could have something that should be four different detects. And you kind of get, distracted along the way. So careful of the scope, for this scenario.
In terms of the research, this is fairly straightforward. And what we need to research and how to detect this is, really just going and looking at the different command flags for psexec was pretty clear that there is a dash P flag that, you, you use to pass a password in psexec and then also researching should this happen.
So in some cases, I’ve, I’ve heard some things from some of our defer folks here that PS exec is evil and you should never use it. I’m not going to say whether or not I agree with that.
But the ultimate point being what is the best, practice for this specific case. So psexec P, what does that look like?
Is that good? Is that bad? Should that happen? Should it not? long story short, you definitely should not be doing this. if you don’t pass the dash P flag, it requires an interactive password, which is what you’re supposed to do if you’re doing things in this way.
Having it on the command line in plain text for anybody to see, is not ideal. why would the attacker run it in this way? I mean, a good example is in this case it was run through a batch script, so it’s way easier to just run it in mass with a bash script this way.
And plus they wouldn’t even necessarily have to be at their computer for it to run either. So you have your research, kind of what you want to look for. the flags, what it is that you want to try and detect.
And you might have some sample logic at this point. Now’s the time that you need to be formalizing your query. So this is the bread and butter of your detection. It is, the most important part in a lot of ways because if you don’t have a good query, you’re not going to have any good output.
So should be informed by your research as much as possible. as you’re researching, you’ll also be seeing things that you might want to exclude. Like say for example, as we’re researching this, we notice that, hey, one of our, users or one of our legacy applications has to do it this way.
That’s not great. but that’s, that might be part of your research that turns up and things that you do and don’t want to include. You, could have a number of queries as you go and kind of evaluate the different results of them.
We’ll do that at a larger scale later in this process. But for now, kind of running some basic queries to get an idea of what the results looks like, is a good idea. You don’t want to get a query and then, run it across five minutes and think, hey, that’s awesome, and then move four steps down the line just to find out later you’re not actually seeing what you need to see.
You, might also have a choice in query languages. Now is the time that you need to pick that. So, we use elastic, so KQL, EQL, EsQL, Lucy and like a billion other languages and whatever one they come up with next week.
in this case, I won’t spoil which one we’re going to use for this detection. But the point of this step, for your query is you need to find a balance.
So if your query is too broad, you’re risking burnout, you’re risking high volume. You’re going to maybe even have, too many events that the key ones that you want to look for are buried in that giant mess of tickets.
if you have too many tickets also your SOC will really not like you. the middle ground is what we’re aiming for, obviously we want a volume or we want to balance, really good balance between volume and fidelity.
We want our detection to look at everything that we want to see, but we also want it to, have a very high rate of when it fires, it being a true positive.
on the other side, if you’re too narrow, you’re too specific, you could miss small things. So if you look for dash p and the password is in parentheses or quotations or something like that, right.
That would be an example of being too narrow. Or you look for dash P and they pass a file beforehand. There’s a number of examples for this case that might be too, too broad, too narrow.
the goal would be again that middle ground, finding somewhere in the middle to where you’ll see enough events, but you won’t see so many that your detection has rendered itself useless due to the volume.
for this detection scenario, kql not Kusto. This is Kibana query language. this one has a very simple and straightforward way of looking for something like this, the process name field and the process arguments field, which is, an array or a list, can’t remember, but it will have this dash P as a separate value within this process arguments field.
as you can see in that screenshot. so in our case, if we search process name psexec and the process arg of P, any case that that comes up, with an argument of P, this will pick it up regardless of what the other arguments are.
So that is an example of that good middle ground as we’re not too specific, but we’re not looking at all P.S. exec. if this were a production, detection, I would also highly recommend doing a couple other things such as lowering the process name field all to lowercase that way, you’re matching on everything, no matter how it’s capitalized.
And then also looking for, some PS exec knockoff names. or maybe, better yet, theorizing a little bit, there might be a way where you could look for an execution similar to this, maybe looking at the command line like arguments as a whole, and then also seeing the PS exec service getting installed.
So there’s a lot of ways you could get more specific into this. but for our case, for this scenario, this example, it’s super straightforward.
So process name and the argument dash P now is where the rubber kind of meets the road, is you need to validate that your work so far, is going to turn in something that you that you want.
So I mentioned it a little bit. But estimating your volume before you onboard and publish a detection is absolutely something you need to do before your SOC comes to you with, pitchforks and torches.
And, that’s not, it’s not something you want. So what does this look like? This is something that, some places do and some places, I mean, you might not have ever heard of doing like a backtest or a backfill or whatever it is you want to call it.
So what this looks like to me is I would want my query then run against 90 days of previous data. So 90 days as ideal. 30 days would be the absolute minimum.
but you need to look back and see what this detection would look like, in the past, historically, for as long as you really can, honestly. Right. And so as you do that, you might, discover things that you would need to filter out.
You might say, oh, shoot, we have, this customer does this thing this specific way. Should they be doing it, should they not be doing it? Or maybe in some cases you would, talk to them about it.
but in other cases it might be something that you filter. And in some cases you might end up having to rewrite portions of your, your query based on this backtest. Unfortunately, another thing that I definitely recommend when doing this back testing step is you should save your results.
If you don’t see any results in your backtest, document that somewhere, Document it in your, documentation that you’re doing as you go, right? Doing that as you go. Keep, have a screenshot, have your query, have your time period that you did.
That way if it starts firing off the hook later, you can say, hey, I did my due diligence, right? there may be, like I said, some unfortunate cases when you do your back test.
if the volume is extremely, extremely high, you might have two options to you, you could end up, or maybe three options, I guess you might end up having to just drop the detection idea as a whole.
That’s not unheard of. alternatively, there are two different ways that you could really go down. So one of them being you could have this as a lower priority detection than maybe you originally intended.
That might suck. but it’s better than no detection in a lot of cases. And so having it as a lower priority than you originally said, you at least are still getting that visibility.
alternatively you could reassess your query. So maybe there is a way for you to reformulate Your query and avoid a lot of the noise. Look at common fields between all the events, stack the data, look at what’s occurring the most.
And if you care about it, you could be looking at the stacked data and go, hey, every single time we see this and it’s legitimate, this flag is also here or it’s run from this location and stack the data, see what stands out, see what’s the most common across the board and try and consider what you can and can’t filter to get rid of all that noise.
For this scenario, the scenario I ran was just the 90 day backtest. There were zero results, which, this is either the best possible result or the worst possible result.
So best possible result being. This is very high fidelity. This is awesome. The worst possible result is something is very broken, either the SIM or my query or maybe just me.
if you’re looking closely enough at the screenshot, you will notice that I didn’t just search the process name and the argument, I also searched a username and specifically excluded that username.
So I have zero results because I excluded actual malicious traffic from, from this query. So that is showing me that my query does in fact work because it did pick up the malicious traffic before and I just had to exclude it.
someone put in. Is KQL case sensitive? Yes, there are some ways to get around it, but most of the time it is case sensitive. So careful of that.
so that is our, that is our backtest currently for this scenario. What you need next, and this one is so often forgot about, is a canary.
So what does a canary do? It validates that your detection is working, from, this point into the future. So once it gets deployed, the last thing you want is for it to stop working and you to never realize that it stopped.
Maybe a, field value updated or some sort of mapping changed and it’s been broken for six months. And you only find out about it once an attacker does exactly what you were supposed to be detecting.
So a canary fills that gap. It is code that will execute ideally on a schedule to validate that your detections are working as intended. This logic can be really simple from just running a singular, singular command on the command line to being something super wildly complex or, or compiling some sort of C application and doing all this sorts of weird stuff within it to fire off some alerts.
ideally like I said, you should be running it at an interval and you should have reporting configured for if it fails to send an alert. So that’s kind of the difficult part for some people is when you have this canary and it is in production and it’s running and it’s running on a schedule, it needs to alert you if it fails.
Otherwise again, it doesn’t, doesn’t, doesn’t serve its purpose if it doesn’t alert you. Because if, you’re not going to see that this has failed. It’s, it’s not, it doesn’t help you.
It needs to be able to send you an alert on a failure. if you haven’t heard of the Atomic Red Team, I have some homework for you. Go look at it. They have a ton of canaries in here that are for a lot of different things.
you can also make your own. It’s very simple. so if you haven’t heard of art, go check it out. I think the Antisyphon, I think that Antisyphon does have some courses that are specifically related to art and other similar concepts.
So also check those out. but in terms of your canaries there you can have the best possible setup, which is, you have dedicated infrastructure and scheduling for your canaries.
That is the best. Because the infrastructure will never be the cause of your detection failing because everything will remain consistent. If you’re running it on different infrastructure, there will always be additional variables and then that’s when you have to try and figure out, hey, this detection canary failed.
But why? Was it the infrastructure? Was it the canary? Was it the detection, like what’s broken? So the most variables you can remove from your canary environment and your testing, the better.
if you cannot do that advanced of a setup, just running your canaries regularly scheduled or manually like that is better than nothing. You will know and eventually find rules that have broken for one reason or another.
So running them regularly is still very viable. The worst, option that I would not recommend is testing your rule once and then releasing it.
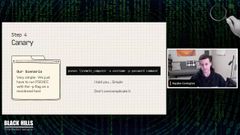
it may work in that current moment when you’re testing it, but that doesn’t guarantee that it won’t break tomorrow. for this scenario, again, super easy.
It doesn’t have to be complicated. You don’t need to over complicate things with your canaries. They, they are a validation step. All they need to do is confirm that your detection works. And for this case we just need to use PSEX with the dash P flag.
Simple. I would recommend that you try and execute the activity as close to what it would really look like as Possible. There have been some cases where I’ve been working on a detection and I go, hey, I could do it this way.
And I, echo a command out to the command line, which would trigger the canary. But if you go and look at the logs that it’s generating, it is not actually the logs that this tool or technique would really generate.
so I would highly recommend without, sending malicious traffic and running botnets and, miners, generate as close to the true traffic as you can. That way you, for a fact that it looks like what you are trying to detect.
someone mentioned capturing data and replaying it. If you have the setup for it. That’s, that’s pretty near perfect is, presenting the real data.
That would be super ideal. The only danger is if that data is, pulling out and it is a, kind of a place in time where you’ve captured this data.
You would want to make sure that something hasn’t changed in your setup and Windows and whatever system you’re in. That way a simple change doesn’t, because if you’re running it on static data, your detection will realistically always work.
that data could change, maybe psexec changes in how it runs in this example. Right. So running it on the real traffic that you’ve extracted is a great idea.
it just, you will need to be careful to validate that things have not changed. And so in my case, I generally will just run the command as near as possible without doing anything truly bad documentation.
Everybody’s favorite step, I’m sure it certainly is mine. And that’s not sarcasm. anytime that somebody, asks me for notes on something, I guarantee I have them hear your groaning, I hear you getting upset and throwing your laptop on the ground and wondering why you’re here.
documentation is extremely important for detection engineering. Extremely important might, be the most important step. So it needs to spell out everything that your detection needs to have documented about it.
You need to explain why you filtered certain things. You need to explain how to investigate it. you need to have all these really important details, not just for you, but for the SOC, for the people that are going to be responding to these alerts.
That is extremely important because nothing sucks more than, opening up a detection in the SOC and going, I don’t know what this is even looking for.
You, have to then go and spend some of your precious time trying to research this alert, as the alert is already fired. And if it’s a real attacker, you’re wasting time. So having good documentation that clearly spells things out, and spells them out succinctly is very important.
And for that reason is why I recommend the ADS framework, which is alerting detection strategy. So ads, it’s open source. Make sure you covers all the bases.
Covers everything from, big picture down to specifics. Very great idea. And as you’re documenting things as you go, a lot of what you’re documenting can get dropped down into your ADS documentation as you go.
I have the link there on the page to the ADS framework. I also have the link at the very end of this presentation. Again, that is the ADS framework. It’s open source, looks something like this.
And this is our example. So the ADS doc for this one is fairly straightforward. we have a goal, we have some categorization with categorization, easy for you to say, which is links to MITRE techniques specific to this sort of attack.
And then we also have a strategy aspect, a technical context, which includes the detection logic. And then we also have some information about blind spots, like how could an attacker potentially get around this detection?
And then it goes on further. I didn’t have enough space to put the whole thing on here, but this is the basic ADS documentation that I wrote up for this, mock detection here.
so covers a lot of bases and near the bottom there is actually steps that explain how to investigate this alert. super helpful for the SOC.
And I saw someone mention it in the discord. Spoiler alert. You can write these with AI. I wouldn’t recommend dumping it from AI right into your true documentation.
you should definitely be reviewing it and validating that it is true, as you always should with everything AI. But I wanted to give a huge shout out to Wade Wells. We were chatting at Wild west and he showed me that you could just generate, an ADS doc on your phone through a custom GPT.
He made I have the link in the slides and at the end, he also just posted the link in the discord. That ADS doc from the previous page was made with AI. I put in write me an ads, for this detection logic.
And I gave it my detection logic and then it spit out an ADS document, copied it right into VS code, and then all I had to do was edit a couple of the sections. There were some parts where it got, more wordy or it wasn’t specific enough, for what I specifically was looking for.
But honestly, it probably saved me at least a half an hour writing this document just because it built the format for me and it had all the, all the meat of the documentation there and I just had to get more specific, narrow it down, Again, highly recommend that custom GPT you could make your own, if you would prefer, you could make it in something like, like fabric.
You could ask it, you could give it the the ADS framework. You can template it out. You can do this in a number of ways. You don’t have to rely on OpenAI, you could do it locally.
but either way, check that out. That is super awesome. I highly recommend the ADS framework, especially if you can get the hard part out of the way up front.
Onboarding. I consider this a separate step in detection engineering. Some people don’t. I consider this a separate step. So this is the, this is a step in my mind where you actually onboard your detection into the sim.
And this is fairly simple and straightforward and sometimes people will just breeze through this step. In my opinion, that is the wrong way to go about it. So it is very important to be careful in how you are onboarding your detection into your sim.
You shouldn’t paste in the query hit on like, that’s not, it’s not what you should be doing. Even if you’ve researched it thoroughly, you still need to make sure that you’ve configured everything correctly. That might seem straightforward to some people, but I wanted to make that, for folks that aren’t as experienced in detection engineering.
There are plenty of things that could get missed if you breeze through this step. So you need to ensure that you’re, suppressing correctly, throttling correctly. depending on your compliance requirements.
This is where you’d make a change ticket or a pull request. And this is something that Black Hills does. I would definitely recommend a burn in period, which a burn in period is just going to be where your detection is in the SIM and it’s on, but it’s not cutting tickets yet.
It might not even be outputting alerts yet, but at the very least it would be in the SIM and it would be running and you would be able to see the output. And so you would know, oh, hey, I forgot to suppress this field.
So every time someone runs PSEXEC P, I get 1 billion alerts for that user. That’s not what you need. You need one alert or per event, even if that event involves a number of different entries.
you only want one event, one alert. So that is what onboarding generally is for this case. Fairly, straightforward and elastic. Looking at, endpoint logs or Windows logs.
you might only need one of those. It depends on your setup. but in this case, you add in the query and then I’m suppressing by host and username what that means if you’re newer to Detection Engineering is host and username are the two fields that if they are the same for each time the rule runs, it will only generate one alert for that pairing.
So if Hayden, laptop, slash Hayden generates a PS exec alert and then I run it 90 more times within this rule run period, I will only get one alert cut for that, which is good.
That is what we want. As your SOC investigates this thing, they’ll see all the other events that occur. You only want one alert. Otherwise, while they’re trying to investigate this one, you’ll get a billion more that are just the same thing and they’re nothing but distracting.
So suppression buffering. you want to align this to whatever fields are important to your setup. you would want to be careful though.
because if you suppress too far, you might be missing important things. I find host name or username or host user. User is about as deep as you would want to go. The more specific you get, the more risk that you have of just flooding the queue.
The more, broad you get. like if I were to just go organization or domain, like that would be risky because if there’s 10 different threat actors on a network and all of them are doing this thing, you’ll only get one alert.
in that situation, I would want an alert for each threat actor. That way I am, sufficiently alerted and sufficiently aware of what’s going on.
inelastic. I’ll point this out. It’s not super important to this general concept, but there is an elastic field to suppress if, a field is missing. So in this case, what that means, and I’m explaining it just because it’s in the screenshot, that means that the username does not exist.
It, will not suppress. So make sure that your fields exist. That’s part of that onboarding and burn in period is the field might not exist for the log source that you’re looking at continuous improvement.
This is the last step, but it runs forever. Detection Engineering does not or should not stop when you hit enable or approve. There’s a number of reasons you might come up with new research.
You might find new filters that need to be applied. you might need to make fixes, things might break. as you go, you should be updating your detection. Make sure to keep it within the scope.
But as new techniques emerge, maybe you find, another piece exec clone that comes up and you want to cover that one. That’s part of your continuous improvement.
for large changes, if you change a core part of the query or you change something fairly substantial, I would definitely recommend that you do maybe another back test, maybe do another burn in, depending on how big that change is.
but your, your detection life cycle doesn’t stop. It’s a continuous improvement once you onboard it. and then that brings me into something that is the favorite of everybody in security.
Right behind documentation is risk management. you can’t catch everything. You need to find a balance. when you’re filtering, when you’re making a detection, you will always have to find a balance.
There will always be risk involved. You need to develop detections that you can manage, but also, that detect everything you need to detect. I have some of the generic, risk management phrases here, avoidance, transfer, all that sort of thing.
even as you’re filtering, you should be having these in the back of your mind. you would want to make sure that you are filtering appropriately to where you’re not allowing extremely high volume.
But you’re also, at the same time, you’re not filtering too specifically. So you want to find that middle ground for your filtering. That way you are not exposing yourself to too much risk.
for this case, for this scenario, our risk, is very low. And for this scenario, for a continuous improvement, I’m just adding a rule exception.
So for this rule exception, say that I, the special IT admin that I am, I, need to use psexec this way because I don’t want to do it the other way. M.
Let’s pretend that this is the scenario. so in this case we want to exclude that because that is known activity and the security team doesn’t need to be alerted every time I do this thing.
That’s expected. You are accepting some risk in doing that, right? Like if all of a sudden I turn coat and I start, hacking everything, you might not pick up if I’m, if I’m using P, is exact with the dash P flag, right?
But hopefully your detection stack is expansive enough that one detection like this, one filter like this is not going to make or break you.
you, you should have Defense in depth. That’s another one of those key terms to where if you add a rule exception, you understand there is some risk inherently with this, but it is not going to expose you to too much.
And maybe in some cases this is too much risk. maybe what you do instead is you tell me, Hayden, you’re not special. You can’t run PS Exec this way. it’s all dependent on your organization.
But if you have enough defense, enough detections that are layered and defense in depth, again, you don’t have to worry too much about little things like this, again, this continuous improvement.
Things like those filters, they can be brought about by plenty of things, they can be brought about by your SOC operations, your SOC ticket work. a lot of our filters in our SOC are brought about by SOC analysts because they see something in a ticket and they say, hey, we probably don’t need to see this because of X, Y and Z.
And they submit a ticket to the detection engineering team. They evaluate it and determine whether or not that should be filtered from the alert or from the detection. So that is one, one source, new research is another one.
And then these changes can, range fairly from filters to suppressions to just full overhauls. And as you go, you will always have a change in detection.
Just be prepared for that. your detection at this point has become a theory though. So that’s where we’re tying it back into that scientific method. Right? Your detection is a theory now because it’s been carefully researched, you’ve scoped it very definitively, it’s well documented, it’s reproducible, and it’s continuously evolving to meet with new information.
So that is how it’s a theory. I told you it would come back together and wrote back into the scientific side of things. hopefully you understand the theming of this presentation at this point.
Now I, wanted to hit on the resources again. I have links to the ADS framework, to Wade’s ads, chat, GPT bot, and then I also have a link to a splunk detection talking or a splunk blog, blog talking about detection as code.
I mentioned approving pull requests. That is where the detection is code thing is kind of coming from where some places are moving towards doing their detections in a repository where changes are managed and pulled and has versioning.
So I think that is really where detection engineering is going. So I would check out that blog, keep an ear out for that, check out some Other webcasts. And then I do have. I did mention my course.
That course is through Antisyphon. We’re teaching it in December at the Secure Code Summit. And then we’re teaching it, live in Denver in February. And so that course is Foundations of SOC, specifically with elastic and Jira.
These slides are all pulled right from that course, throughout that course. The whole point is we will be building a soc, building detections, triggering canaries, investigating the results.
so you’ll be part SOC engineer, part SOC analyst, part SOC manager, because we’ll work on grabbing metrics and things of that nature, too. And so that. That’s all pulled right from my course.
That’s why I’m so excited about it, is because this is a topic that I enjoy talking about. and that’s all I have for today.
Jason Blanchard
Well done.
Hayden Covington
good job, buddy. Thank you.
Jason Blanchard
All right, so we have time for Q and A, which I would love to get to. Plus, we got James and Paul and, Will joining us. So, someone asked, are there other elastic courses in development at Antisyphon?
That’s an interesting question.
Deb Wigley
Get all that love.
Hayden Covington
I think that I’ve talked with some people that have considered making some courses. I don’t know how many of those are being fully worked on at the moment.
the only one that I know of for sure that is about to come out is mine.
Jason Blanchard
Hayden, do you do extreme couponing? Because I think you’d be really good at it.
Hayden Covington
I don’t even know what that is. I could see. Oh, no, I do know what that is. I would be really good at that.
Jason Blanchard
You would be amazing as extreme couponing. You would leave with eight grocery parts full of stuff, and they’re, like, handing you cash.
Hayden Covington
I would, yeah. Yeah. The problem is I would get so bored doing the couponing. At least this stuff keeps me entertained.
Jason Blanchard
All right, so first question here. Also, if you didn’t get your question answered, Paul and James and Will were, essentially backstage answering questions, and some of them were saved so we could get to them.
But if you did not get your question answered during the webcast, please ask it now to make sure that we know that you still want to get it answered. Because sometimes the content answers your question.
Hayden Covington
Yeah.
Jason Blanchard
All right, so how important is purple teaming slash adversarial simulation at phase zero of your detection engineering process?
Hayden Covington
I always do that first. To be perfectly honest with you, before I start writing a detection, I. If it’s something complex that I don’t quite know how to Detect, that’s the first step I do is I generate the traffic because then I know exactly what it looks like and how to research it.
That’s a little pro tip. I built some, some stuff that was pretty stupid complex and built off of, specific attack tooling. And in some cases those tools do so many different things that it’s almost impossible to detect them off of one event.
And so having a full view of what that tool running looks like is really the only way to know how best to detect it. So the one that I was looking at was the one that always comes to mind right away is a tool that backdoors images in aws.
And so to figure out how to detect that tool, I had to run that tool and backdoor some images on a monitored device just so I would know what that traffic looks like and what I should connect to try and detect when that occurs.
Deb Wigley
so there’s a follow up, same, same attendee once. A follow up to my previous question. Supposing a detection story comes from in lab adversarial simulation, how do you avoid falling into the trap of your canary being the same as your initial detection story?
Hayden Covington
Yeah, where was that question? Was it in, it’s in the.
William Corbin
It was in Zoom, but I copied it to the private webcast chat above.
Hayden Covington
Trying to find it, because that one I need to. That one I need to read. That one’s a complex one.
Deb Wigley
It is a complex one. So if you go to that private webcast chat right above webcast chat, webcast live chat channel, you should be able to see it.
Hayden Covington
Yes. Which one was that one, Will?
Deb Wigley
The one second from the bottom.
Hayden Covington
Second from the bottom. Okay. how do you avoid falling to the. Okay. I mean it doesn’t have to be a problem. So if you’re, if you’re doing adversarial simulations and you’re generating malicious traffic through that, as long as you’re not actually performing malicious activity, like you’re not actually exfiltrating data to some, some domain that you don’t own, there’s nothing wrong with running those tools.
So if you have a environment that you use for testing for your canaries, there’s not necessarily anything wrong with running mimicats as long as that you’re not actually doing anything evil with it, you may still be able to generate enough logs to get a good detection that alerts on what Mimikatz truly does.
Which is also good because if you were to set that up in such a way where you Pull Mimikatz and then you run it. If Mimikatz ever changes down the line, you will know it. If it breaks your detection pretty quick, Wade says just let it fire and.
Deb Wigley
Then close it as testing Black Hills official response, but.
Jason Blanchard
Huh.
Deb Wigley
Ok, here’s another question. Have you had elasticsearch frequently go into a weird shard overload? I fought that on every logging implementation.
Hayden Covington
Yep. Will, I’m sure can back this up. I’m apparently notorious for destroying our elastic cluster by trying to use esql.
I have a whole slide in that in my class about how I once crashed the whole cluster because I made one ESQL search and then, our detection engineer publicly shamed me to the whole SOC about it.
so now anytime any shards fail, somebody asks if I’m using esql and unfortunately one of the times that answer was yes.
William Corbin
So he got blamed twice.
Hayden Covington
I’ve been blamed correctly for it twice. But to answer the question, yeah, it is. I mean, it’s a reason that that’s a job. That that’s a job. Specialization is being an elastic engineer is because it is.
It is not easy. it is. It is not easy. Especially as you scale like our elastic cluster, is pretty big. And so the scale of that makes it infinitely more difficult.
And I talk a little bit about that. Again, don’t want to be a broken record, but again, in that class I talk more in depth about all these things. We stand up that cluster and talk some about the management of it.
but that is a class that I would like to see on Antisyphon. It’s just dedicated to being a platform engineer because that is something that doesn’t get enough love, I don’t think. I’ve done some splunk engineering, some elastic engineering, and it’s hard.
It’s. It’s not. It’s not easy. It’s easy to set up initially and get data in there because that’s how they charge you. of course that part’s going to be easy. But as soon as you get into more complex things and you’re building connectors and shipping data and maybe the data isn’t normalized, it starts to get complex pretty quick.
Jason Blanchard
While you guys are, gathering your next question, I just want to say to everyone, make sure you check in for Hackett today. Hackett’s our program where we keep track of how many times you’ve engaged in discord live during a webcast.
And so if you haven’t checked in for Hackett and you’re like, I Have no idea what that is. as long as you’re posting in Discord, it counts. And if you’re like, why do you keep track? well, it helps us know how many of you come and, but the other part is that we want you to engage in Discord when the webcasts aren’t happening.
And so this is an opportunity for you to ask questions. The same questions you’re asking right now could be asked during the week or when you run into a problem that you have at work. And so you can ask those questions and then the community will help answer them for you.
So thank you to the contributors and community leaders here on the Discord server that help consistently and kindly answer questions. This is a place where for you to not know how everything works and ask in a way that’s anonymous in the most part.
so that way you can then get the answer to your question. All right, speaking of questions, who else?
Hayden Covington
I do have. I do have two that I want to answer. one of them is from Frank says, for step zero as part of the data sources, Are there instances where the process stops there and goes on to mention, like, if the EDR is a data source, do you stop there?
that depends on your setup. Like, we’ll run the elastic edr, which might have some detections. and we do have alerts on EDR alerts.
but in my opinion, if you build your own custom detections, you can get a lot more specific. Sometimes those EDRs are a black box and you cannot influence them. And maybe you can, but you need to pay an extra $9 billion per user to enable to do in order to be able to do so.
So, in some cases, yes, if you’re. If you’re crushed for time and your EDR detects it, you can, just have your EDR detect it. That’s the whole point of paying for it.
But in some cases, that might not work. I would just say that. Run that test activity, if you get to that point and see what your EDR spits out. but again, I would be.
I’m usually wary to rely on the EDR vendors to, to handle things for me. I prefer the control myself because I know what’s coming in and what I’m putting out, and I have full control over it.
the other question that someone put in, how do you see mllms enriching or altering the detection engineering process? Will it be less manual or require any additional skills to be successful?
I mean, to put it plainly, detection engineering could probably be done fairly well by AI at this point, from start to finish. the real, the real kicker is going to be validating that it still runs, that it still works.
And same with all AI having that human touch to make sure that it’s actually doing what it needs to be doing. So you can generate the documentation with AI fairly simply.
But even when I did so, it wasn’t 100% correct. There were a couple things that it didn’t quite get. And it might have gotten it if I gave it, a couple hundred more lines of information about what I was trying to look for.
But I think currently the risk still exists that the AI will be wrong or it will not be 100% right. And if you don’t, I would not want to risk my entire network security on the AI being 100% correct.
I think that it can supplement it and make the boring parts easier for you. But I don’t think that you should be relying on it 100% yet.
Jason Blanchard
All I heard was rely on it 100%.
Deb Wigley
Rely on AI.
Hayden Covington
I mean, I use AI for everything. I use it a lot. but I still don’t trust it.
Derek Banks
I came in halfway to that. And I would just, add that, just a kind of like devil’s advocate kind of thing, that I agree that AI can be wrong for sure.
and I use it pretty heavily too. But also just, I mean, just as a general rule, as a tech worker, like, don’t believe everything you read. Stack Overflow can be wrong.
The AI can be wrong, your coworkers can be wrong. I’ve had all be wrong.
Deb Wigley
Wait a second.
Derek Banks
So I’m just saying that, like, I think you have to verify everything. And so I would definitely use AI.
Jason Blanchard
Yeah. And also, Derek, didn’t you give a talk yesterday on AI so if someone wants to grab that recording.
Derek Banks
Oh, yeah, Joff and I did, yesterday. And we have a class coming out, and we’re teaching the class at the Secure Code, Summit.
And the, the Wild west hack infest in Denver in person.
Jason Blanchard
We should definitely put a link to the Secure Code Summit, which is free, and then two days of paid training afterwards.
Deb Wigley
Are you doing.
Hayden Covington
I’m answering questions in the in zoom M. All right. Some. Somebody asked one more question that I wanted to hit.
or two. Sorry. one of them asks how often do you visit suppressions and exceptions? It should be fairly regularly. I would say you, run the risk of having a suppression cause you to miss an attack.
that is why I appreciate elastic adding timed exceptions. So I can put in an exception that only lasts for a week and then it turns off. So for, short lived things. That’s awesome.
there have been cases where, we were suppressing things that we probably would want to see just because the suppression’s been in there for so long and it gets kind of forgotten about. So as often as you can, I, would review those suppressions just to make sure.
At least do it once to make sure that the ones are in there, should be in there. And then someone asked about rba. I saw Paul, answer that question. But we talked about that at Wild West Hack Infest.
A lot is if you have risk based alerting, which is effectively alerting based on risk scores coming in from your alerts. It’s been, We’ve talked about it a lot.
I won’t go off onto a tangent, but if you have risk based alerting, your detections with high volume could be lumped under that. So you could have a detection that there’s no real good way to tune it and it generates way too many alerts to go straight into your, your SIM and your ticketing system.
You could lump that under risk based alerting and you could still get an output from it. It just wouldn’t necessarily be every time it fires. It would be maybe if it fires in conjunction with these other things, you’ll get an alert for it.
Jason Blanchard
one other thing. I mentioned this at the beginning during pre show banter, but there’s hundreds of you not here. If you’re currently hunting for a job and you’re in Discord, please put the word hunter into the chat. and then we’ll give you a special role that unlocks a message board where people can post jobs.
So if you have a job that you want to post for the community because you’re looking to hire somebody, there’s about 50,000 people on the Discord server. And so out of that there’s some active people and they might have the skills that you need for the job.
All right, so I’m going to wrap up Hayden. I always ask the presenter if you could, take everything that you’ve said today and have one final thought, what would it be?
and then we’re going to stick around if you want to stick around at the end. the SOC team is here and we brought them in today so that if you have questions about hiring Black Hills to Be your SOC.
We’ll, answer those questions then. We don’t like to do it during the webcast because during the webcast, we like to keep it completely as educational as possible. So, Hayden, if you could wrap up everything in one final thought, what would it be?
Hayden Covington
I would say that if you have a structured process for your detection engineering and you, you do it well, and it’s well thought out, you will have a much better output at the end.
Jason Blanchard
Excellent.
Deb Wigley
And so much.
Jason Blanchard
What?
Deb Wigley
no, I was said I was making a joke about how you want to trust AI for everything.
Jason Blanchard
Thank you so much for joining us here today on this Black Hills Information Security webcast. We appreciate you being here. We know there’s a lot of other places you could be and a lot of things you could do with your time, but you chose to be here with us. So it, says a lot about you wanting to learn more.
we love having, the best defended, clients that we get a chance to work with. And so if that is, a desire of yours, we’d love to be your SOC.
And so if you ever need us, where to find us. And with that. Okay, the webcast is over. Well done, Hayden. Good job.
We’re now in post show, so I’m gonna give everyone eight seconds. If you do not want to be a part of learning what it’s like to be a, SOC client of ours, if you don’t have any desire to ever be a SOC client of ours, then this is your time to leave.
If you’re like, I just want to listen in and hear what you guys have to say about your SOC. Because I work at a SOC and I do. Guys do. so eight seconds.
Eight, seven, six, five. four, three, two, one, zero.
Sometimes people are like, why do you give people a chance to leave? I was like, because I don’t want to hold anyone hostage that they don’t want to learn or hear. just. Okay, so what we’re about to do is tell you what it’s like to be a SOC line of ours.
And here’s why. Every once in a while, people don’t know what we actually do. They show up to these webcasts time and time and time again, and they think we’re a webcast company or training organization, which we are.
Or they think we’re a, WABAS hack and fest, which we also are. Or a publishing company, which we are also are. We make zines or backdoors and breaches, which we also do.
and they’re like, so what do you do here? And it’s like, well, we have an active soc, we have an anti soc, we have pen testing, we have all these different services. And so we show up every once in a while, like once a quarter, and say we also have a business.
Deb Wigley
So very good at marketing, I think, is what I heard.
Derek Banks
Yes.
Jason Blanchard
Also a clothing brand also. So, Derek, what is, what’s our SOC? What do we do? How’s it work?
Derek Banks
I mean, I think, the general idea is that we want to be your security partner to help you detect, potential breaches in your environment, which is probably the goal of most SOCs.
and so I think that, we have a blend of clients. Some use us as a second soc, some use us as their primary SOC. And so the motivation that a company would have to, hire us in or contract with us to do the SOC, would, b.
To augment their team. They have a small team or they just need a second set of eyes. Kind of like a blend of customers that we’ve had, both large and small.
And so will your SOC detect? Your red team actually was on a call with a client, as a pretty big client. Like they have probably three or 4,000 endpoints, and they actually had their.
The folks that will be doing their pen test, this year. We don’t know when we got invited to kind of like the ROE and scoping call kind of thing, and like, to kind of like work like purple teamy with them.
And which we’ll. We’ll do. And, we were introduced as the only SOC that’s ever caught their previous pen test. So will we catch, every red team or pen tester?
No one can ever tell you that. Right. I don’t necessarily always care about catching pen tests and red teams. I’d rather catch real threat actors.
And yes, we can tell the difference. So.
Jason Blanchard
someone asked, do you provide managed SOC for clients outside the US Are, we only US based or.
Derek Banks
yeah, we provide, so we’re 24 7. We do have folks who work the graveyard shift, so to speak. And I don’t know of any restriction that would prevent us from, providing SOC services for folks outside of the.
Jason Blanchard
U.S. someone asked, do you have a link to a white paper data sheet on what you can provide as a SOC? And so that’s where I’m like, oh man, I suck at marketing.
Derek Banks
so we don’t really have a white paper that is like downloadable and out there. And I mean, it’s not just you, Jason. I think it’s the rest of us to providing you with the content.
You can’t just make it up. Right. I mean, we do have obviously stuff on our website, but usually what we ask, just like with our pen test. I don’t. I don’t know that we have that for the pen test side either.
For any thing that we have. If you don’t know, we bhis. actually, we own quite a few companies, not all information security related and so, but usually what we do is we ask that you just meet with us and we’ll talk about it.
So.
Jason Blanchard
All right, so we got people that work in the SOC. And what do they. What do they do all day? Derek, what does the SOC do all day?
Derek Banks
Well, I think that my job is quite different than, I would say Hayden. And if. Is Paul still here? I can’t. I don’t have it set up.
Yeah, Paul and Will and Hayden have, probably different takes on what it’s like to work in the SOC. I’ll be honest, the vast majority of my day to day work is going to meetings, so that’s kind of.
So I will let Paul or Will or Hayden, talk about their experiences in the SoC, because I don’t want to speak for them.
Jason Blanchard
All right, Will you first?
William Corbin
Oh, yay. so most of our day in my experience is dealing with at the base level. We’re looking at alerts, as they come in for our customers on our detections.
we’re actively investigating any activity we think is suspicious, looking through the customer’s logs. if we’re not doing alerts, we’re pretty much trying to do threat hunting or looking into new detections that we could possibly catch new things with.
Jason Blanchard
So.
Derek Banks
That is a fantastic answer.
Jason Blanchard
It is. Well, I don’t get a chance to work in the SOC environment. I don’t have those skills. Thankfully you do. but when you see an alert does, like, your heart start to race and you get excited because it might be something.
William Corbin
Depends on the alert, to be honest. we actually do get excited when we see potential active threats to us that.
Hayden Covington
Oh, yeah, go ahead, Derek. Can I. How much can I mention about the excitement from Wild west without naming specifics?
Derek Banks
you can talk about all of it as long as you don’t disclose the who.
Hayden Covington
Okay. So. So at Wild West Hack and Fest, I, think I was eating dinner and somebody from the SOC walked by me and said that something Bad was going on.
and so upon walking into the green room, there was about very quickly, six or seven of us in there, and there was a very active attacker on a monitored network.
Jason Blanchard
Okay, I saw that. And you guys were having the best.
Hayden Covington
Time, to be perfectly honest with you. It was a lot of fun. So we get in there about six in the evening and we are on with the defer guy, we’re on with the customer, and we are identifying compromised machines, hosts, providing to the customer, the defer guys in there too.
And it, eventually John Strand himself kicks a bunch of people out of the room because it was getting a, little hectic, but I didn’t want to leave. I think three of us were there, four of us were there until like 7ish the next morning.
It was exciting. I wanted to see it through. And so in those cases you see it and you go, well, I think Derek nailed it on the head when he said we can identify pen testers.
When I look at a ticket, I’ve looked at so many, I’ve been doing this long enough, I can almost always tell right away whether it’s an attacker or not. And if it is, I can almost always tell right away if it’s a malicious one or not.
And in that case I looked at it and I immediately went, oh, and that’s one where your heart races. Yeah. No, if a pen tester did that, what we saw, they should have been fired, to put it simply.
Jason Blanchard
All right, awesome. Derek, question. back to you. do we only deal with big companies or is it anyone that needs us as a service?
Derek Banks
Anyone that needs us as a service.
Jason Blanchard
Yeah.
Derek Banks
In fact, when we first started, and I think this is probably still true, it’s not that we wouldn’t turn away a larger company. I mean, we certainly have some pretty large folk or pretty large environments.
but we were trying to cater to small and medium sized businesses because, at least historically speaking, I won’t say that it’s 100% true these days, but at least historically speaking, managed SOCs, were expensive and then internal SOCs are very expensive.
And so we try and keep our prices relatively reasonable. And I think that usually what I say is the, the idea is that, it’s now depending on size for sure, and how much data that we’re, pulling in for you, but roughly an F is what we shoot for, or if you’re larger, maybe two FTEs and you get access not only just to our SOC and our expertise in our SoC, but you also get access to other folks at BHIS to ask questions about not necessarily SOC things through our BHIS expert support team kind of stuff.
Jason Blanchard
Here’s a question from audience. How hands on are you guys as the SOC when it comes to active attackers or remediation, do you stick to a learning and providing recommended of courses of action or do you actually get hands on and start mitigating, isolating devices locking out.
we are on the call with.
Hayden Covington
You for the next 14 hours.
William Corbin
That is a great question. We will do whatever our bosses let us do.
Derek Banks
Yeah, so I mean it just.
Hayden Covington
We want to get more involved. Derek has to tell us it depends.
Derek Banks
On the organization and what they want us to do. It depends on if they’re going to claim cyber insurance. It depends on things. Right. I mean the idea is that we get you into a situation where we, because when you come on board we do an active directory review and we look at your IR plan, we look at, we try and cover, we ask lots of questions about what your network looks like and what your environment looks like.
we try and make sure that we’re logging the big five areas that we want to see data. We log the network as well. Like we want you to install a Zeek sensor. and so the idea is that we never have to remediate anything however that I mean, I know it’s probably shocking for folks who are in the consulting realm that companies don’t always do what we ask.
And so this last one that was breached, yeah, they didn’t do the things that we asked them. It was a bad, bad day for them. But we still, we still caught it.
But we offer an IR retainer like kind of built into our, our soc, statements of work, our SOC contracts. And so if you had an incident and you wanted us to investigate it, we will totally help you do that.
As far as actually like we’ll help you contain and we’ll help you like, get to the point where you remediate. We actually don’t offer remediate where we would come in and help you like rebuild your domain controller or something like that, that’s kind of where we would stop, is kind of like the recovery phase.
Jason Blanchard
and I think my last question, in case the audience has any additional questions, it looks like a couple are coming in. But my question is, we started off Black Hill started off as a pen Testing service company.
How does that offensive mindset bleed in or, or give vision and direction to the SOC that we have?
Derek Banks
Well, it certainly helps me identify, pen testers versus actual threat actors. Right? Like, oh, I’ve seen that command. I’ve used it before because I did pen test for what, seven, of my ten years at Black Hills.
and so, and before that I was in a SOC. So I’ve been kind of on the blue side, then the red side, then back on the blue side side. And I feel like that whole wealth of expertise from being.
If I had a question about how an attack worked and I’ll be arbitrary, let’s say active directory certificate services and abuse there. And I wanted to know details.
I can literally go hop in a team’s chat with all the testers and just go talk to them. We have relationships with them. We go out and drink beer at Wild West Hacking Fest together.
I mean, I feel like that we’re in a unique position because we like, there’s no silo. It’s not like the SOC folks can’t talk to the pen test folks and vice versa. And then, we have our continuous pen test team which they act like actual, like threat actors.
And it’s a long term engagement. once a, quarter, we meet with the, the leadership at the CPT side and they tell us what we didn’t, didn’t.
Didn’t detect or what we didn’t detect. And I mean, it happens, right? I’d be lying to you if I said we catch everything. I mean, it’s impossible to do that. So I mean, we try and work together too, to make detections better.
Jason Blanchard
I mean that’s pretty much what the webcast was about was like detection engineering. Like you try, you have a hypothesis, you either catch it or you don’t. And as you, well, you figure it out and you make improvements.
so Hayden, I would say last question for you. you work in the SOC. This is what you do. This brings you joy. what would you say to someone who’s thinking about having us be their SOC?
Hayden Covington
I think that what Black Hills brings to the table is people that are really passionate and excited about the work, which I don’t think that you’re going to get in a lot of other SOCs.
SOC work is famously very burnout high. And so often you’ll get folks that will send you the most minimal ticket that you can possibly get, if they send you one at all.
And I think it Kind of probably showed through, when I wasn’t kidding earlier. Sometimes the SOC gets told, hey, back off, you’re spending too much time on this. Because, I mean, if we see something interesting all of a sudden, everybody wants to be involved because it’s fun.
And several of the SOC analysts are cross training into defer because we want to do more of this stuff because it’s fun to. And I think that’s the good thing about Black Hills is it’s brought together not just people that are good technically, but people that are really excited about the stuff that they’re doing.
we have a section in our weekly meeting that mentions tickets that we thought were interesting. or, it’s, it’s what we bring that’s different is our, our enthusiasm and our actual care for, for what we’re doing.
I don’t just want to forward you a ticket that your EDR already sent to you. I, want to investigate it and figure out what’s going on. And even if I do need to send it to you, I want to tell you what you should be doing about it.
I don’t want to, leave that out in the open. If I think you should remediate that machine, I’m going to tell you that. And if you’re a SOC customer, you also have deeper retainer hours probably.
So if things are bad enough, you could probably lean into some of those actually.
Derek Banks
Funny that you, you mentioned what happened while with Hack and Fest and then also, like, we have a problem with everybody, like, oh God, that’s interesting. Let’s hop in and look. I mean, it’s a double edged sword, right?
Like on one sense, like I can, look at it like kids playing soccer, right? And chasing. If anybody’s ever had a kid and played soccer, like when they’re young, like you ate, and lower, like they don’t know how to play soccer.
They all chase the ball around the field in like one big pack. Right? but there’s benefits to that. And, and actually when we’re at Wild West Hack and Fest, like the day after I had somebody who wasn’t in the SOC ask me, like, just kind of like in passing, they’re like, are you gonna like, tell them everybody stop working on it?
And like, I mean, like, because, they’re like, it was said basically, okay, everybody stand down like it’s a contained. Which it wasn’t. Right. But okay, whatever.
And, and, and so let’s move on. And I was asked, hey, are you gonna stop everybody from working on it? And I was like, no. Like, I’m gonna let them do whatever they want to do. And that’s how they learn.
And so go look at all the logs you want.
Jason Blanchard
So, yeah, I said this in the last two webcasts, and we’re not going to do this again for a while. But, like, during this conversation, we’ve had a request, to talk to us about being your SOC.
so thank you for sending in that message. You can go to blackhills infosec.com, click on the contact us form. You can also email consulting@blackhills infosec.com and that kicks off the whole process.
And we want to do the do this now because we know that, changing SOCs or getting started with a SOC is not, like, it’s not.
You don’t decide today and start tomorrow. I think we’ve only had one client that was like, I want a SOC. And the next day they started onboarding. so if it’s going to take you a while, it might take you a while.
And so this was just starting the conversation to let we even have a SOC, so that maybe next year or, at some point, you’re like, hey, how about we get Black Hills to be our SOC?
And so we appreciate you listening. There was, like, 250 that stuck around. Derek, any final thoughts? If someone’s considering us for their SOC, this would be the last thing that we do.
Derek Banks
I guess, yeah, if you want to, like, I get more details, like, kind of, what we log, what we ingest, like, how we go about doing things, like, details on.
On what we use. I would just reach out and schedule, a meeting with our business capture team. you’ll likely end up with our business capture folks and probably somebody like me or, another like, like, senior person on the call to ask technical questions, like, exactly how, like, our alert strategy works and which.
Maybe Hayden covered it. I’m sorry. I had to go work during Hayden’s, webcast. I’m sorry, Hayden.
Hayden Covington
That’s okay.
Derek Banks
but, yeah, I mean, I think just if you would like to know more, just meet with us. And to answer the question about, elk and security Onion. Yeah, I do think that’s a good place to start, for learning, network, monitoring, and a little bit about elastic and IDS systems.
Jason Blanchard
All right, Deb, any final thoughts for the community as the director in kindness.
Deb Wigley
And generosity just sprung it on me. just thanks for being here. Thanks for the 280 people who decided to stick around after and listen to us try to do marketing. We don’t know how to do it.
but thank you for sticking around. And we just.
Hayden Covington
We love you guys.
Deb Wigley
We know, like Jason said at the beginning, there’s so many things for your attention, that you could spend your time interacting with. And we just appreciate that you choose us as one of them.
Derek Banks
Yeah, definitely. Thanks, everybody.
Jason Blanchard
Yeah. All right. Thanks, team. Thanks, everyone. Yuri, go ahead and kill it. Unless you killed it a while ago and we were just talking to ourselves.
Deb Wigley
That would be so sad and not unlike us.
Derek Banks
Yeah, that wouldn’t surprise me, actually.
Jason Blanchard
All right, Yuri, kill it. Kill with fire, Yuri, kill it.
Ready to learn more?
Level up your skills with affordable classes from Antisyphon!
Available live/virtual and on-demand
