
Securely Deploying IPv6 in 2020 Part 1: Internet Facing Perimeter
Joff Thyer //

Introduction
If there is anything that the start of 2020 has taught us, it is that Internetworking services are in higher demand than ever before. IPv4 is exhausted, and by that I mean there is none, it is tired, worn out, overused, abused, and beyond its end of life. Besides our heroic attempts at variable-length subnetting which placed an enormous burden on enterprise routers, and exponentially grew the global route table, we still ran out of addresses.
Network Address Translation is equally overused and abused. It is not and never was intended to be a security technology. NAT is simply address conservation, and the fact that we now have globally deployed natted networks behind other natted networks is beyond ridiculous, and more to the point stretching the intent well past its original design. We own a nod of appreciation to all those that have valiantly extended IPv4’s life way beyond its shelf life, but it is truly past time to commit to IPv6.
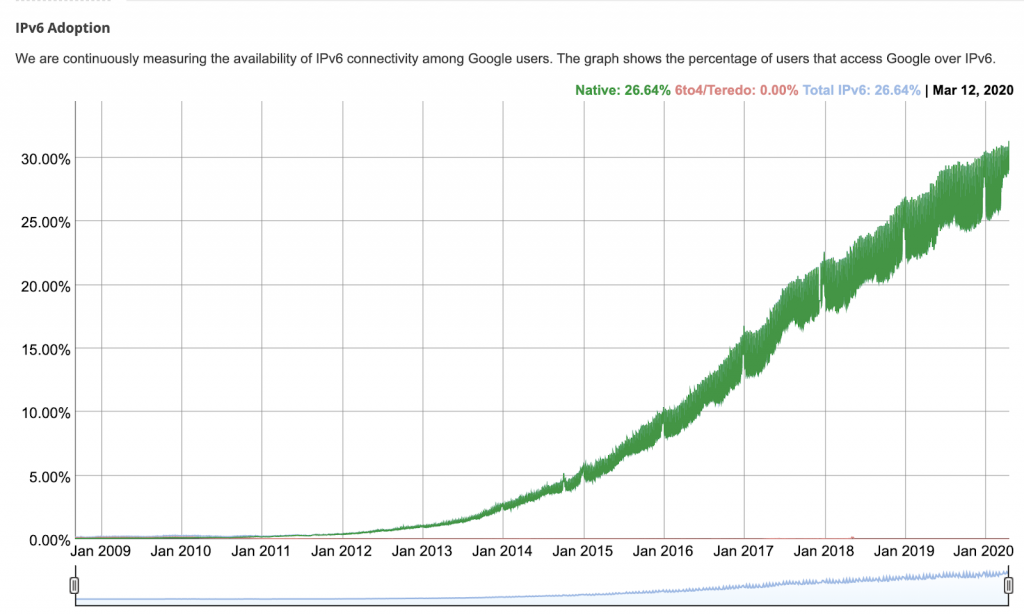
Rather than exclusively give a tutorial on IPv6, I am going to talk specifically about infrastructure security that we must have in place to safely deploy the protocol.
We should start with and understand some of the foundational knowledge. First of all, IPv6 is a 128-bit address space. It is known as IEEE 802 protocol 0x86DD within an Ethernet header, or if encapsulated in an IPv4 header, it is carried as IP protocol number 41. (6 in 4).
As of today, IANA has allocated out IPv6 address space across the world to the various Regional Internetworking Registries which consist of ARIN, RIPE NCC, APNIC, AFRINIC, LACNIC.
For additional background details:
- https://www.iana.org/assignments/ipv6-unicast-address-assignments/ipv6-unicast-address-assignments.txt
- https://en.wikipedia.org/wiki/Regional_Internet_registry
The address allocations are as follows.
- /12: seven IPv6 blocks spread across various RIR’s.
- /16: one block for 6to4 translation
- /18: one block to RIPE NCC
- /19: two blocks, one to RIPE NCC, and another to APNIC
- /20: three blocks, one to RIPE NCC, and two to APNIC
- /22: three blocks to RIPE NCC.
- /23: eighteen address blocks spread across various RIR’s.
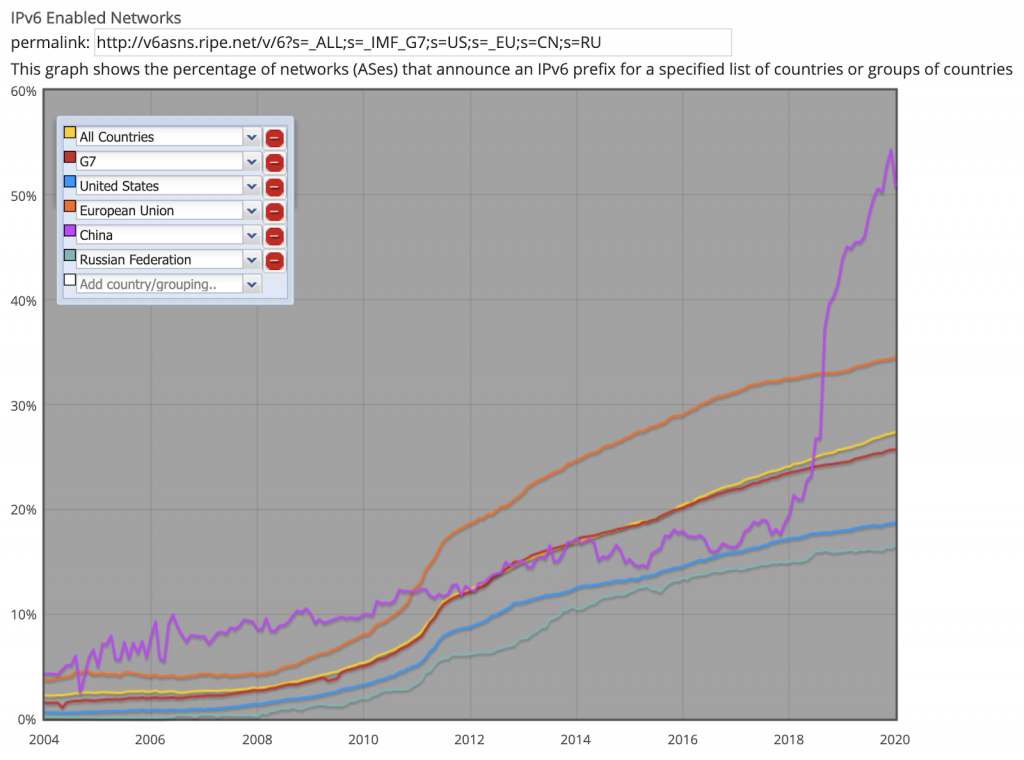
These address allocations are enormous! If only 12 bits are set for the network prefix, then 116 bits can be further allocated by Internet Service Providers. In pure host address terms, that is 2^116 which is 8.4 e24 addresses!
It is the case that most service providers will further allocate addresses in /32, /48, and /64 blocks. Refer to https://tools.ietf.org/html/rfc6177 for more information as this is an active discussion. To view the current state of the IPv6 BGP global route table, refer to https://bgp.potaroo.net/v6/as2.0/index.html.
Right now, it seems that if your organization is multi-homed with your own BGP Autonomous System Number (ASN), you are likely to be allocated an IPv6 /48 which is a whopping 2^80 addresses from which you can further sub-network into /64’s.
If you are single-homed or tunneling, you will probably receive an IPv6 /64 allocation which is twice the size of the entire IPv4 address space and if you desire to do so, you can further subnet this space internally.
I know, you are now thinking that you want in! After doing my initial homework, that’s exactly what I thought. Being a total infrastructure and endpoint security consultant, malware developer, musician, mathematician, and outright geek, I just had to get my hands on this stuff as soon as I could.
So I called up my friends at my local ISP and I said, “Hey guys, I want an IPv6 address block”. And they said, “We don’t carry IPv6”. (cue the “you just lost your PACMAN game” music…)
I am fortunate enough to have a small static IPv4 allocation, so I thought to myself “it’s time to tunnel” so I can build an IPv6 testbed. I went out and started researching, and came across this:
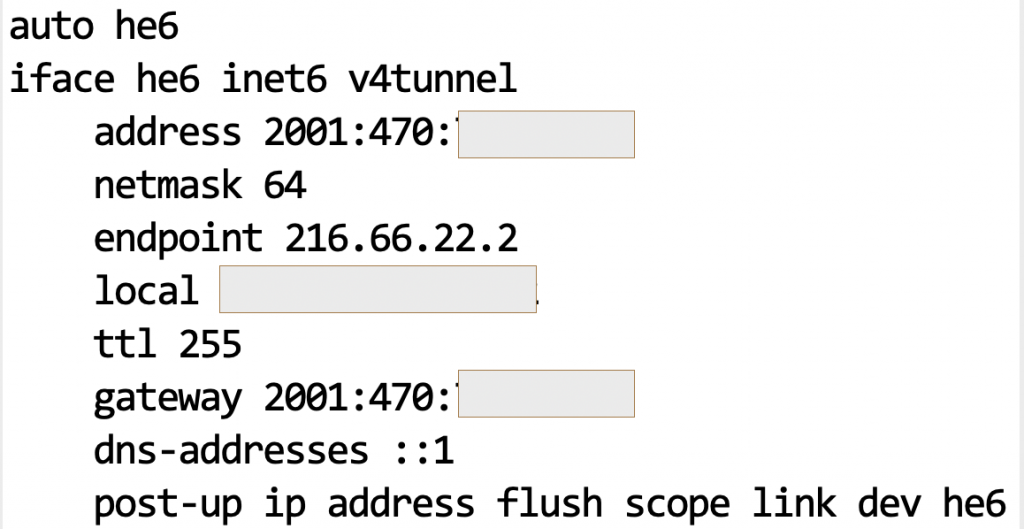
I chose to create an account with Hurricane Electric based on their widespread reach, and literally in a few minutes I was granted an IPv6 /64 address block as long as I tunnel the traffic using IP protocol 41. https://en.wikipedia.org/wiki/6in4
My tunnel interface configuration on an Ubuntu system looks like this. ( well, with a few redactions). You honestly did not think I was going to give you my IPv4/IPv6 addresses, did you?
Now you ask, “What’s the first thing I did as soon as that tunnel came up?”. It’s pretty simple, I installed and configured DNS, because who in their right mind wants to remember an IPv6 address. Not too difficult with a debian Linux to do so: “apt install bind9” will do it but you probably want to adjust your settings to use the local resolver afterwards.
And now for some basic connectivity testing. Wait, who would possibly have IPv6 deployed? I bet the usual suspects of sizable organizations like Google, Amazon, Microsoft, and Research Universities. I tested my local DNS resolver using our friend “dig” after learning how exactly to use it with IPv6. (I kid you not, adjusting your brain out of “v4 mode” is a real thing…)

I think I have my sea legs, albeit wobbly so let’s proceed further. Of course, we need to try ICMP echo request/reply and traceroute. In IPv6 world, these commands in Linux become “ping6”, and “traceroute6”.


After that high-level introduction, let’s talk about security which is where the action really needs to be. I would like to break this down into four important topics, IPv6 Addressing and Scope, Internet Control Message Protocol (ICMPv6), and Perimeter Network Security.
You might notice that Internal Network Security is conspicuously absent. Considering the breadth of coverage here, I decided to leave the Internal Network Security topic for a follow-on article.
IPv6 Addressing and Scope
There are three different kinds of IPv6 address, unicast, anycast, and multicast. Both unicast, and anycast addresses have two different scopes, these being link-local and global. For multicast, the four least significant bits in the second address octet determine the scope. Multicast addresses start with “ff0”, and different scoped addresses are as follows:
- FF00 => reserved/unused
- FF01 => interface local (host bound / loopback multicast)
- FF02 => link local
- FF03 => realm local
- FF04 => admin local
- FF05 => site local
- FF08 => organization local
- FF0E => global
- FF0F => reserved/unused
Internet Control Message Protocol Version 6 (ICMPv6)
Before I start these discussions, we cannot avoid talking about ICMPv6 without which IPv6 just will not work. The first fabulous and exciting revelation is that the IPv4 Address Resolution Protocol (ARP) is gone, and good riddance!
IPv6 is very much multicast dependent for many functions, and a tremendous amount of discovery uses ICMPv6 and multicast together. Similar to ICMP in v4, there are ICMP types, and codes in the packet.
ICMPv6 can be broken down into four categories, Error Messages, Informational Messages, Neighbor Discovery Messages, and Other IPv6 Protocol Control Messages.
- Error Messages
- Type 0: Reserved / Unassigned
- Type 1: Destination Unreachable. The code field contains the reason.
- Code 0: No route to destination
- Code 1: Administratively prohibited
- Code 2: Unassigned
- Code 3: Address Unreachable
- Code 4: Port Unreachable
- Type 2: Packet too big. Important for the path MTU discovery mechanism to work properly.
- Type 3: Time exceeded message
- Code 0: Hop limit exceeded in transit. (Life lesson: Don’t let you TTL expire because you will be dropped.)
- Code 1: Fragment reassembly time exceeded
- Type 4: Parameter problem message
- Code 0: Erroneous header field encountered
- Code 1: Unrecognized next header type
- Code 2: Unrecognized IPv6 option encountered
- Types 5 through 127 are unassigned or reserved for experimentation
- Informational Messages
- Type 128: Echo Request
- Type 129: Echo Reply
- Type 130: Multicast Listener Query
- Type 131: Multicast Listener Report
- Type 132: Multicast Listener Done
- Neighbor Discovery Messages
- Type 133: Router Solicitation
- Type 134: Router Advertisement
- Type 135: Neighbor Solicitation
- Type 136: Neighbor Advertisement
- Type 137: Redirect
- Other IPv6 Protocol Control Messages as defined by various RFC’s. Types 138 – 161 are currently defined. Please refer to https://www.iana.org/assignments/icmpv6-parameters/icmpv6-parameters.xhtml for more information.
- Types 162 – 255: Unassigned, Reserved or Experimental Use
Perimeter Network Security
As you might imagine, with perimeter network security, many of the concepts we used for securing IPv4 can, in fact, be ported across to IPv6. For this part of the discussion, let’s break the topics into categories as follows:
- Allocated Address Space Filtering
- Anti-Spoofing Filtering
- ICMPv6 Filtering
- Multicast Filtering
- Protocol Normalization
- Exterior Border Gateway Protocol Security
- DMZ/Internet Facing Server Address Allocation
Perimeter: Allocated Address Space Filtering
An alternative topic name here might be “Return of The Martians” or “Bogons Live Another Day”. In short, there is a lot of unallocated address space in IPv6 and you should not allow a packet into your network unless it is sourced from an allocated address block.
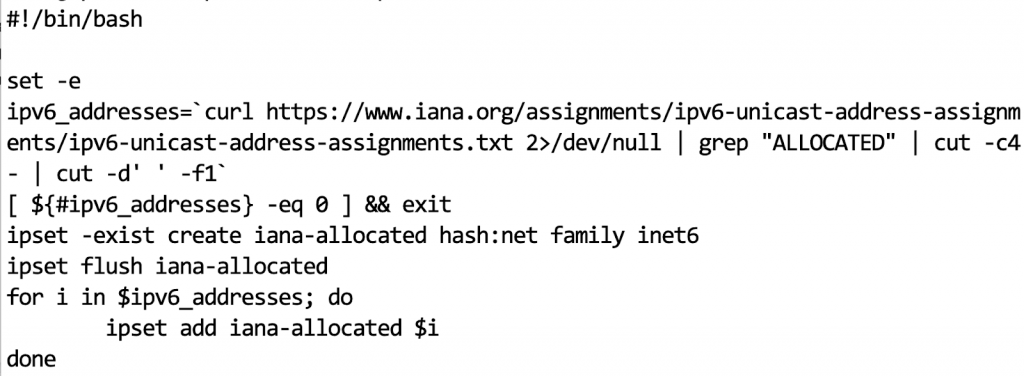
In reality, this is very simple. IANA has today allocated 35 address blocks. You can define an ACL on your perimeter router to only allow traffic sourced from these 35 blocks, and drop everything else. With my Linux tunneled solution, I used iptables and related ip sets, implementing as follows:

Note that in the screenshot above I am assuming that the router (tunnel endpoint) will not only possibly initiate traffic itself, but will be responsible for IP version 6 traffic forwarding across some defined sub-networks in the future.
Of course, any OSI layer 4 filtering will have to be implemented in the above ruleset also so this represents just a baseline starting point. Remember that OSI layer 4 and up with IPv6 is fundamentally unchanged from IPv4.
One more thing to be aware of is that IANA allocations of IPv6 will of course change. In my case, I used a simple shell script to parse out the allocated blocks and update my IP set with the correct data. Because I am a nice guy, I am including that script here.
Perimeter: Anti-spoofing Filtering
The golden rule is that no packet should enter your network that has a source address representing your allocated address block. Equally, no packet should leave your network that has a destination address matching your allocated address block.

Perimeter: ICMPv6 Filtering
As stated above, with ICMPv6 the IPv6 protocol just breaks making the topic of securing ICMPv6 extremely critical not just for the perimeter but for the interior of your networks also. You cannot take the IPv4 style naive approach of just dropping this protocol but rather you need to be more nuanced.
Filtering ICMPv6 can be broken into two categories, that being traffic that is initiated from a perimeter security device, versus that being traffic that should transit the security device. I will keep this portion of the discussion to transit traffic that is important to the perimeter security policy stance of an organization.
Transit traffic you should allow to pass through to/from the Internet. All other transit ICMPv6 traffic should be dropped. These are my opinions combined with interpretation of https://www.ietf.org/rfc/rfc4890.txt.
- Type 1: destination unreachable, you might optionally be selective and pick “port unreachable” code only.
- Type 2: Packet too big. You don’t want to break path MTU discovery.
- Type 3: Time exceeded but code 0 (TTL/hop limit expired) only.
- Type 4: Parameter problem (codes 0 and 1 only)
- Type 128/129: Optionally you can allow ICMP echo request/reply at your discretion but the same caveats as IPv4 apply. If you drop, you can break Teredo tunneling so apply with care.
- Types 144 – 147 apply to mobility enabled networks and can optionally be dropped with an understanding of the loss of functionality.
Another important point is that an organization needs to make a policy and operational decision related to whether the organization wants to participate in global multicast sources. If so, then transit traffic will need to include multicast router discovery, advertisement, and termination messages which are types 151 through 153.
With regard to ICMPv6 messages initiated from the perimeter security device, the above list, excluding the mobility enabled types 144-147 should be allowed to pass. In addition, address selection and router selection messages should be allowed to pass including:
- Types 133-134: Router solicitation/advertisement
- Types 135-136: Neighbor solicitation/advertisement
- Types 141-142: Inverse Neighbor Discovery solicitation/advertisement
- All other multicast receiver, router discovery, and also SEND path notification messages. (refer to RFC)
ICMPv6 Type 137, Redirect Messages represent a significant security threat and should always be dropped. As with any network packet filtering, a default “deny all” unless explicitly permitted is the most sound approach.
If possible, implement packet inspection of the source and destination addresses of any unicast ICMPv6. Specifically, if the embedded payload within the packet does not have a destination address that matches the source address of the ICMPv6 packet, it should be dropped. Conversely, if the embedded packet payload does not have a source address that matches the destination of the message, it should be dropped.
In addition to these filtering decisions, you should always limit the potential for denial of service attacks by applying rate-limiting configuration for all ICMPv6 messaging.
In my opinion, no policy decision is warranted on unallocated, reserved or private experimental messages for ICMPv6. All of these remaining messages should be dropped.
For your information, here are my Linux iptables rules for forwarding transit ICMPv6 across my router which are very ICMPv6 type-specific with an applied rate limiter.

Also below is a screenshot of ICMPv6 iptables rules for handling neighbor and router discovery within the internal LAN. These are deliberately not applied to the tunneled ipv6 interface, and there is, of course, a default packet drop policy beyond that which is accepted.

Perimeter: Multicast Filtering
If inter-domain multicast is not desirable, then strict perimeter filtering is essential. Additionally, any spoofing of packets with multicast as a source address are certainly spoofed and should be dropped. Assuming that your policy is to not participate in inter-domain multicast, then you should filter the following at your perimeter:
- Any packet with a source address that is multicast
- Block/drop reserved and unused/unassigned multicast destinations
- FF00::/16 (reserved)
- FF06::/16, FF07::/16 (unassigned)
- FF09::/16 through FF0D::/16 (unassigned)
- FF0F::/16 (reserved)
- Block/drop all global scope multicast destinations (FF0E::/16)
- Block/drop all site-local scope multicast destinations (FF05::/16)
- Block/drop all organization-local scope multicast destinations (FF08::/16)
- Consider blocking/dropping realm-local (FF03::/16). These will be specific to other RFC’s and must be a policy decision.
For more specific information, please refer to https://tools.ietf.org/html/rfc7346.
Perimeter: Protocol Normalization
IPv6 has a protocol header labeled “next header”. It is possible to continue chaining extension headers together into an extremely long chain of extension headers before the OSI layer 4 headers are encountered.
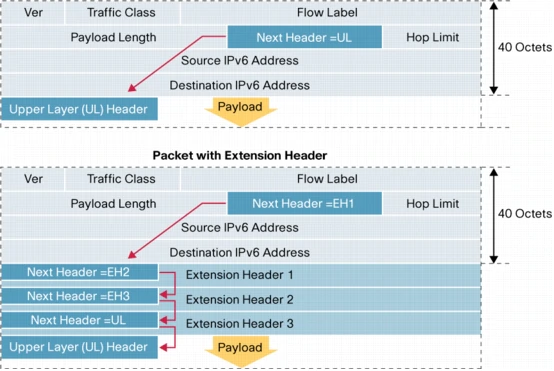
It is possible to create a denial of service attack using long chains of extension headers all of which need to be processed by perimeter security firewalls and/or routers.
Extension header attacks can also be leveraged to blind Intrusion Prevention Systems (IPS) through the prevention of full packet inspection.
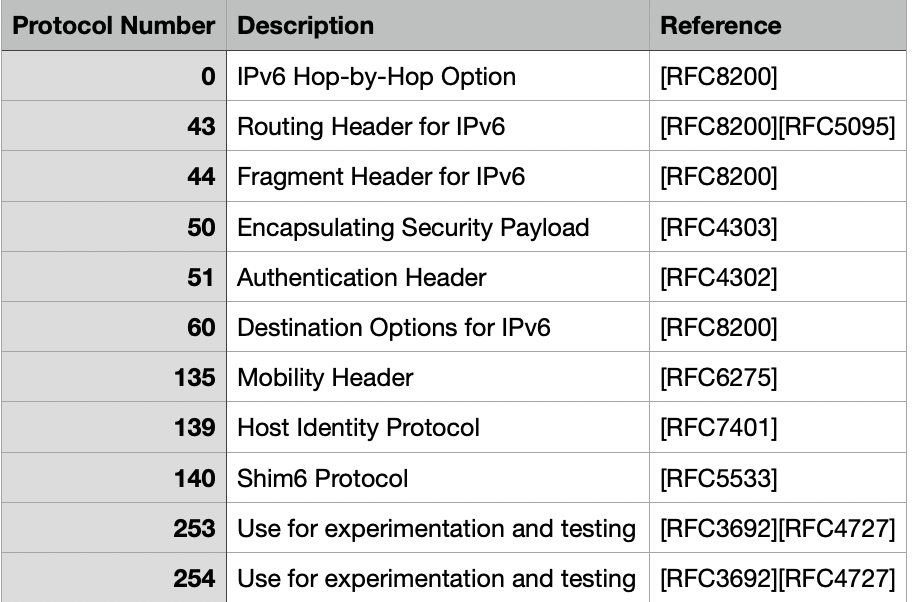
Outside of the above table of extension headers, the normal OSI layer 4 protocol numbering is used for TCP (6), and UDP (17). Absent from the above table is extension header 59 which has a special meaning of “no next header”.
There are some normalization rules which should be enforced by packet inspection devices such as firewalls, and intrusion prevention systems.
- Each extension header should not appear more than once except the destination options header.
- The Hop-By-Hop options header should only appear once and should always be the first header in the list.
- The destination options header should be last in the list and should appear at most twice.
- The fragment header should not appear more than once.
I think it is fairly self-evident that extension headers present security risk if not properly normalized and/or filtered, and also present denial of service risk if processed by packet normalization devices.
One particular security concern presented is the use of the Routing Options Header (43) along with type 0, known as an RH0 attack. Routing headers are very similar to IPv4 strict source, and loose source routing options which allow an attacker to specify a particular layer 3 path through which to route a packet.
Worse still is a use case whereby the same address can be included in a single Routing Header multiple times setting up a potential packet oscillation and amplification attack.
Within both the destination options header and the hop-by-hop options header there is a possibility that padding options (PADN) might be included to pad to an 8-octet boundary. These padding options must always be set to the value of zero, otherwise could be seen as a covert channel mechanism.
Summary Recommendations:
- Ensure that a packet normalization device (firewall or IPS) is able to enforce the extension header rules listed above.
- Drop any traffic that contains a Routing Options Header (43) with type 0 (source routing).
- Drop any traffic wherein padding options within destination or hop-by-hop extension headers contain data other than zeroes.
- Drop any traffic that contains extension headers that are reserved, undefined, or otherwise used for experimentation and testing.
Exterior Border Gateway Protocol Security
The border gateway protocol (BGP) is still with us and widely used for both IPv4 and IPv6 wide area route tables. Fortunately, with the introduction of the IPv6 route table and the leveraging of class-specific address boundaries, the size and processing requirements are significantly less than the highly fragmented IPv4 route table.
Similar security concerns for deploying BGP in the IPv6 world as have been present with IPv4.
- Use explicitly configured BGP peers
- Threats include TCP sequence number prediction because BGP is a long-lived connection.
- Use hash-based peer authentication. MD5 hashes are still common.
- Optionally leverage an IPSEC tunnel for peering.
- Use loopback addresses for peering
- IP peer address cannot be easily determined through traceroute
- Filter BGP peer traffic based on packet hop limit (TTL). The peer router will send BGP with a hop limit of 255 so only accept BGP traffic that has a hop limit of 254 and higher.
- Filter the prefix length being received. Most providers will just filter based on /32 and shorter or a specific prefix length.
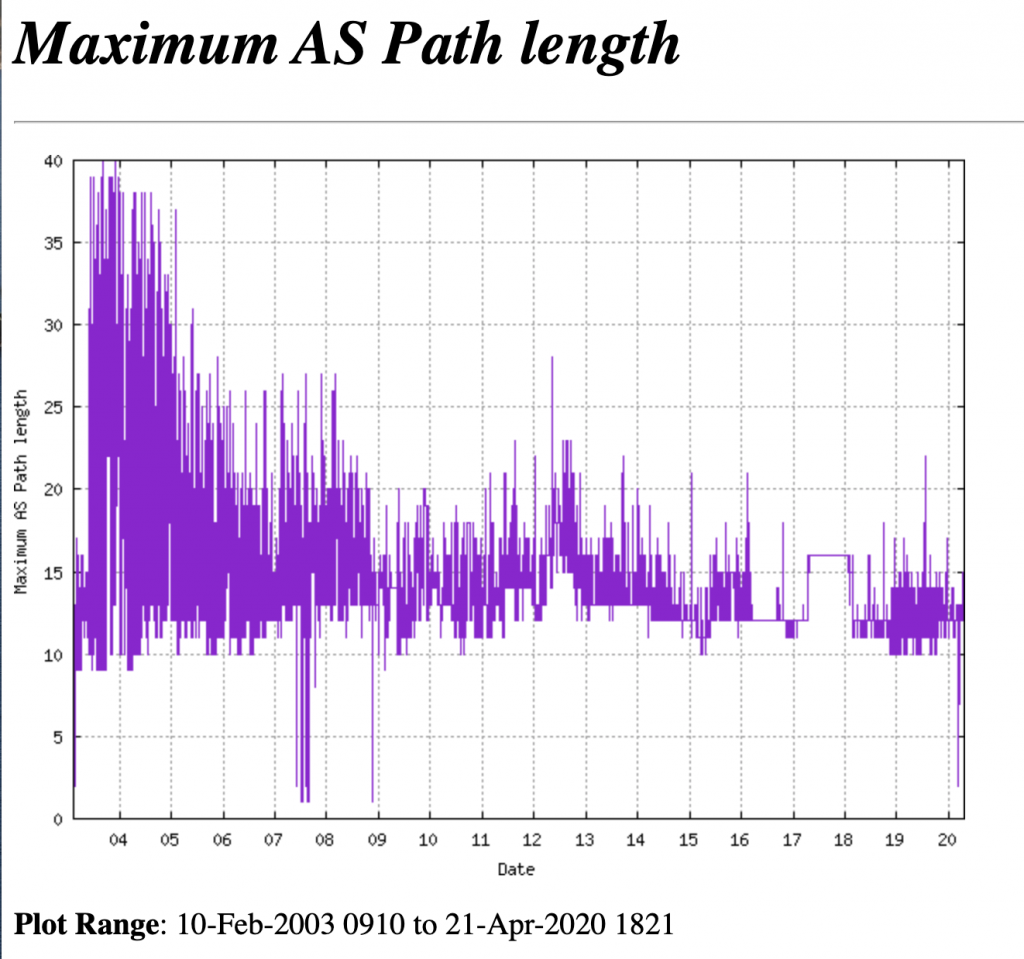
- Filter long autonomous system number (ASN) paths. Using some form of route policy map can be used to enforce AS paths to less than a specific length. A number at or around 40 should be plenty. See below graph from https://bgp.potaroo.net/cgi-bin/plota?file=%2fvar%2fdata%2fbgp%2fv6%2fas2%2e0%2fbgp%2dmax%2daspath%2dlength%2etxt&descr=Maximum%20AS%20Path%20length&ylabel=Maximum%20AS%20Path%20length&with=step.
- Filter private AS numbers in routing updates. IANA has designated AS numbers 64512 – 65534 as private.
- Filter reserved AS numbers in routing updates (0, and 65535).
- Log BGP neighbor activity!
- Disable ICMPv6 Neighbor Discovery (ND) between BGP peers. There is no need for it.
- If at all possible, consider deploying Unicast Reverse Path Forwarding checks (URPF). In strict mode, a packet must be received on an interface that the router would use to route a destination/return packet to. In loose mode, a packet must be received on any interface that is contained as a destination somewhere in the route table.
Perimeter: DMZ/Internet Facing Server Address Allocation
Once you have secured your address allocation, you probably are dealing with either a /48 or a /64 address block. Now, of course, like any other organization, you are welcome to further sub-network this allocation however you please.
Whether in a cloud-hosted situation or your own DMZ/Internet-facing deployment, I would recommend you keep the sub-network fairly large in size. You might choose for example to carve up your /64 block into /72 sub-networks or similar and perhaps allocate one or two of these for your organizational DMZ.
When you perform subnetting, while your router gateway address will probably be predictably allocated for consistency, it is highly recommended to allocate your server addresses in a random fashion. This will mitigate the risk of server discovery during the scanning/reconnaissance attack phase. Since the address space is so vast, this becomes in effect a “sparse” allocation making discovery significantly challenging.
You would also want to statically address your server rather than depending on IPv6 Stateless Address Autoconfiguration (SLAAC) which is more suitable for client-side station address allocation in a residential ISP context. In a managed organizational context, operators will more likely prefer DHCPv6 for address allocation due to the extra control than can be exerted.
You could even go as far as to randomly change your address allocation as long as you retain the ability to efficiently update the associated DNS infrastructure.
An alternative to this would be to sequentially cluster your static addressing choices toward one portion of the address space. Perhaps, for example, starting from one address different from the router address. This would fall under the category of predictable address allocation, and such knowledge would potentially speed up resource/asset discovery.
Tools for Infrastructure Security Testing
As we progressed through this article you can already see that I have used a number of tools for testing and probing purposes. Some are included in a standard Linux distribution whereby some more advanced tools are not.
- Scapy python packet crafting and research tool. (http://scapy.net)
- Ping6 (linux built-in)
- Traceroute6 (linux built-in)
- https://www.si6networks.com/tools/ipv6toolkit/
- https://github.com/vanhauser-thc/thc-ipv6
Some of the toolkit orientated tools mentioned above are more focused on LAN/Internet Network attacks in an IPv6 context. The general internal network security posture is in fact significantly compromised the longer we remain in a dual-stack (IPv6/IPv4) environment. Unfortunately, like so many things, this part of our work is going to be the hardest migration phase to tackle for many unless you are lucky enough to be operating in a greenfield.
Conclusions
There is no doubt that there is enough depth of experience for us to take the plunge into the world of IPv6. Organizations should definitely be looking at providing Internet-facing services with appropriate protections available in the IPv6 domain. Residential internet service providers are already struggling to continue with any IPv4 and will continue to move towards IPv6. This leaves us with internal network security concerns which I will write about in a future article.
Many different sources of information were used in constructing this article which include:
- IPv6 Security by Scott Hogue (Cisco press)
- https://www.apnic.net/community/ipv6-program/ipv6-bcp/
- https://www.team-cymru.com/
- https://www.iana.org/assignments/ipv6-address-space/ipv6-address-space.xhtml
- https://www.cidr-report.org/v6/as2.0/
- https://bgp.potaroo.net/index-v6.html
- http://v6asns.ripe.net/v/6
You can learn more straight from Joff himself with his classes:
Regular Expressions, Your New Lifestyle
Enterprise Attacker Emulation and C2 Implant Development
Available live/virtual and on-demand!
