
Intro to Data Analytics Using SQL

This webcast was originally published on November 21, 2024.
In this video, Ethan Robish discusses the fundamentals and intricacies of data analytics using SQL. Viewers will gain insight into SQL’s capabilities for data exploration, aggregation, and the use of window functions, as well as how to enhance data analysis through advanced SQL techniques. The video also introduces DuckDB, a powerful tool for data analytics, and provides practical examples of SQL queries to enrich and manipulate data effectively.
- The webinar introduces data analytics using SQL, covering the basics of SQL, types of databases, and practical examples of SQL queries.
- Ethan emphasizes the power and versatility of SQL as a tool for data analysis, highlighting its widespread use and applicability across different types of databases.
- DuckDB, a relatively new analytical database, is introduced as a tool that is easy to install and use for SQL queries, making it a valuable asset for data analytics workflows.
Highlights

Understanding SQL: Language, Pronunciation, and Applications
Exploring SQL's role in querying databases, its pronunciation, and its significance in cybersecurity and database management.

Transactional vs Analytical Databases: Key Differences
Explore the fundamental differences between transactional and analytical databases, focusing on data structure, storage, and use cases.

DuckDB: The SQLite of Analytical Databases
DuckDB is a lightweight, server-less analytical database offering SQL capabilities, easily integrated and run from any environment.

Understanding the Power of SQL SELECT Queries
Explore the versatility of SQL's SELECT query for retrieving data, assigning aliases, and performing calculations.
Mastering Data Organization with SQL ORDER BY Clause
Learn how to efficiently organize and sort data using SQL's ORDER BY clause, allowing for multi-level sorting.
Mastering Data Filtering with SQL's WHERE Clause
Learn to filter data using the WHERE clause and Boolean logic, ensuring accurate query results with correct syntax.

Decoding SQL Query Structure and Execution Order
Understanding SQL's syntax and execution order is crucial due to its structured, yet clunky, query writing requirements.
Understanding Rolling Averages and Window Functions in SQL
Explore the calculation of rolling averages, sums, and counts in SQL using window functions for dynamic data analysis.

An Overview of Data Joining Techniques
Learn how to enrich, filter, and expand datasets using various data joining methods like inner, outer, and cross joins.
Full Video
Transcript
Jason Blanchard
Hello, everybody. Welcome to today’s Black Hills Information Security webcast. My name is Jason Blanchard. I am the content & community director here at Black Hills. And today we got Ethan. Ethan Robish is going to do the webcast today, and it’s called Intro to Data Analytics Using SQL.
All right, so if you joined us today, there’s a good chance that you want to learn this topic, and Ethan is a good person to teach this topic. So whenever we reach out to our, technical team and we say, hey, what would you like to give a webcast on?
Normally it’s like, what do you find exciting? Or what are you passionate about? Or what? What’s something that now that you wish you would have known six months ago? Or, like, what do you think would be really beneficial to the community to know?
And we give everyone the opportunity to create their own topic. And Ethan decided to do this one. So here’s what that means. Ethan loves this kind of stuff. And so as you’re listening today, realize that the person who’s teaching you today loves this kind of stuff.
And if you love this kind of stuff, then cool, we’re all best friends now. and please stick around in the Discord server or attend future webcasts and then we’ll become best friends then. If, you see us at a conference, always come up and say hi.
And if this is your first time here, thank you so much for joining us today and spending your hour with us. And for that, I’m going to turn it over to Ethan so that he can actually do the webcast instead of me just talking about all the other things.
Ethan, are you ready?
Ethan Robish
I’m ready.
Jason Blanchard
All right, I’m going to head backstage. If you need me at any time, just go ahead and ask for me or I’ll just jump in if anything bad happens.
Ethan Robish
Sounds good?
Jason Blanchard
Yeah. All right, I’ll see you in a little bit.
Ethan Robish
Thanks, Jason. And thanks to everyone, joining me today to learn about SQL. So we’re going to go over an intro to data analytics and learn a little bit about, this language called SQL.
After we discuss a little bit about the background of SQL, we’re going to talk about different types of databases and why you might choose one type over another. Maybe you didn’t even realize there were multiple types and you could kind of break them up into categories.
Next, we’re going to start just diving into a data set and, using SQL to do some data exploration, in data science parlance, also called exploratory data analysis.
And Then finally we’re going to dive in and do some data, data analysis with the select statement.
All right, so a little bit about me. I’m a former pen tester from Black Hills, former developer for Active Countermeasures and Microsoft. And more recently, most recently I’ve done threat hunting, detection engineering.
I played the assistant to the platform engineer who runs our Elastic cluster. but in one common thread through all of these is there’s, I’ve been introduced to SQL, which is just kind of fascinating when I think about it.
There’s some aspect that I’ve run into in each of these roles and I actually used to actively avoid SQL. I thought it was clunky and not something I really wanted to learn.
But it’s been over my last few roles, the last few years that I’ve really kind of come to terms with how powerful it can be. And I still think it’s not super, super nice to use.
It’s a little clunky, but there are some definite benefits and reasons to want to learn it and to use it.
So, speaking of the SOC, we have a SOC. If you didn’t realize that we do. And we’ve got several different things that we offer. Not going to go over all of these, but if you’re interested, feel free to feel free to reach out to us.
And without further ado, let’s get into talking about SQL. So what is SQL? What do you think of when you hear the word SQL? Maybe you think SQL, instead of pronouncing it SQL, maybe you think of a specific database that you’ve heard of or worked with Postgres.
Maybe you’re a red teamer and you hear SQL and you automatically, your mouth starts watering at the thought of injection and pulling out private information from a vulnerable web application.
Or maybe you’ve actually had some introduction with the actual language. So SQL stands for Structured Query Language and it’s what’s used to query a lot of these databases.
So yeah, structured databases.
SQL itself, the language is kind of, it’s, it’s broad, encompasses a lot of different operations that you can do and you can kind of break them down into different, different areas.
the first we’re kind of looking at here, Data Definition Language. So creating your tables, dropping tables, removing all the data from your tables. This is kind of all things about hey, what can I do with my schema?
And then, and then you’ve got your data query language. So these are all subsets of SQL again. And really data query language is just select. And that’s, that’s honestly what the majority of what we’re going to cover.
I mean I think, I think I may have one other, one other query that I use. But select is what we’re covering in this, in this webcast.
Why would you want to use SQL if you’re familiar with Excel? Maybe you’re a kung, fu shell. Kung fu, maybe you like writing Python scripts, R scripts.
why would you choose SQL instead? So one reason is it’s just, it’s widely used, it’s ubiquitous. I mentioned a couple databases already, but I’m sure you’ve heard of a few more that use SQL.
And the cool thing is there is actually a standard for SQL and these databases strive to adhere to that standard. So when you learn what that means is when you learn SQL for one database, it’s really easy to take that knowledge and apply it elsewhere.
Like if you move jobs or you, your current job changes technology stacks, maybe you move teams. It’s just, it’s broadly applicable. so the languages, the language itself across different databases does change.
There are different, variations. I think each database has its own special features that they add. And I would say I don’t know of any databases that fully implement the SQL standard.
maybe a few of them claim to, but there are going to be slight differences. But the bones of the language that you learn will apply.
So SQL itself is declarative, which is kind of cool, as opposed to programming in something like Python where it’s imperative, where you would say hey, I want to do this operation followed by this operation.
you give it step by step instructions. SQL is different. You just tell it, hey, this is, this is what I want my data to look like. I’m describing how I want the end result formatted and then you send that off to your database and the query planner, the query engine, which is usually highly optimized, figures out how to actually get the data from the database and present it to you in the way that you say you want it.
The third reason is SQL is very interoperable. it’s probably a corollary to it being so widespread. Almost any programming language that you might want to use has a way to use SQL to get data from a database.
It’s kind of the age old way to store and retrieve data. SQL is also very powerful. Tons, tons and tons of features that you can use and you can get some pretty, pretty long SQL queries. I was actually, I think there was a few SQL queries I was looking at.
There was hundreds of lines long like they can, they can get just as long and complex as like a screen. but, but oftentimes it’s more because of its declarative aspect, it’s even more concise than what you would end up doing in a traditional way.
All right, so why might you not want to use C? Well sometimes it’s just the wrong tool for the job. And I’m not saying SQL is the hammer and now you gotta treat everything like a nail.
You certainly can try. but sometimes it’s just easier to go a different route. So in the name SQL Structured Query Language. if you’re dealing with, dealing with unstructured data, unstructured data is always a pain.
But structured data and there are ways, especially the types of databases that they, with unstructured data and clean and normalize your data.
But it might not be the best tool. once, once you get your data cleaned and normalized and looking more like might be your go to, you might be working with an existing data store.
Oh, actually I forgot to mention a couple things. Let me back up. So these are some of the databases that you’ve probably recognized. You may not know. These are more security relevant and they all actually have some form of SQL that you can use to query them.
So that’s, that’s pretty cool. however there are databases or like sims and data stores that don’t use SQL.
Like if you’re, if you’re working with that is used to query the tool where your data lives and then SQL would not be the right, the right tool for you.
So my third point, I want to put a little bit of I mentioned the hundred line long SQL queries.
Sometimes it might be easier to do what you want, especially if it’s a complex algorithm, some, some novel algorithm. it might be better to implement into a traditional programming, programming language.
But on the flip side, SQL, you can definitely do complex analysis with SQL. and I hope to kind of give you a taste of that as we go through this webcast.
SQL is easy to learn, hard to master. So this is a diagram that just shows how deep you can go, into the rabbit hole.
And one thing I find really funny about this. So, null is way at the top, one of the easiest concepts, right? Like the concept of nothing, which should be pretty straightforward.
Oh, but what’s this? There’s also A null at the bottom, the lowest level. So unfortunately null is often crops up in many languages, SQL included, with a bunch of special cases that you have to learn and deal with and will eventually bite you.
But all right, let’s talk about different types of databases. So there are other ways to categorize databases, but the way I’m going to talk about is transactional versus analytical.
So transactional, it’s probably what you’re more familiar with. It’s more, more common. It is the examples that you’ve probably heard of are the examples of databases that you’ve heard of are probably transactional.
databases like listed over here. So the data in them is usually smaller than what you would get in say an analytical database. Not to say small, but smaller.
these databases traditionally typically store their data in row format. So all the, all the fields in a single row are stored together in the underlying file store, which just has consequences of like how fast the operations can be.
And anyway, it is, they are also optimized for getting single entries like a single role row.
So you want, hey, I want a record for this particular customer. And you can, you can pull that single row very fast. Likewise you can update individual entries.
So those are all typical workflows for a transactional database. On the flip side we’ve got analytical databases which is what, going to cover one of, one of these here in this, in this slideshow, in this presentation.
So the data is typically denormalized. So that if you talk about normalized denormalized, schema, it just means that the data is duplicated.
So instead of trying to reduce duplication by having separate tables and using joins and stuff, in an analytical database you’re more typically going to have denormalized data with duplicate fields, columns in multiple different databases.
And that just helps with the speed and the types of use cases that you have for this type of database. And I mentioned the data size is larger.
so we’re talking now about terabytes of data or even petabytes of data. In these types of databases, underlying data is typically stored.
So instead of row, like all the data stored together as a row, all the columns are stored together. So like everything of the same data type. And if you’re more interested in like that aspect, my last webcast that I did last year on log analysis in the parquet format might give some more interesting tidbits, about that.
Okay, so DuckDB is one of these analytical Databases that we were just talking about and it’s really kind of cool. It’s basically the SQL Lite of the analytical world. So SQLite is an example of a transactional database and DuckDB is a example of a analytical database.
And just like if you ever interacted with SQLite you can just, you don’t type in SQLite and you don’t have to have a server or anything, you just run it, you can create a file that’s all your data stored in the single file.
DuckDB is very similar in that aspect. Likewise if you’ve ever done programming and had to pull in a quick database, most programming languages will have a library where you can just say import SQLite and you’ve got a library like a dll or a shared object that gets loaded into memory and it’s just SQLites, code that loads.
It’s an in memory in process database. again DuckDB is very similar. you can do the same thing. You can just import DuckDB and then you’ve got the power that DuckDB offers, integrated with another language.
so installing DuckDB is very, very simple accordingly like you can just, you can just download a single binary and you’ve got it on your system. And actually that’s what I did.
for all these examples in the slides it is now stable so that it’s relatively new database. It doesn’t have the history as some of these others that I’ve talked about.
But it is in version 1.0 now. It’s like version 1.1 I think, but it’s past its 1.0 release. So they’ve stabilized the format and the API.
So if you’re worried about like oh is it going to keep changing every time they release new version? I mean it’s not going to break things, they’ll probably add new features but.
All right, so what does this look like? Well if we’re on a shell we can just run DuckDB and that drops us into a prompt where we can type in SQL.
So we haven’t talked about what a SQL query is or anything yet. But this is an example of a SQL query. You can just type it in and run it and you’ve got, you’ve got it executing in an interactive session.
So on the right here is another example of what you can do. So this is all running from just a terminal or a shell and you’re calling DuckDB and instead of just over, like over here, not giving any Arguments to drop into interactive mode.
We’re going to give it a query. So this s, is the same query we were using over here or a variation of it. And you can actually change the output that you get.
So you can have CSV output, you can have JSON box, there’s several other output mode. So you can see how this can make this useful with, for interoperation with other tools.
So maybe you, maybe part of your data processing pipeline, could, could be used with, with DuckDB and then it outputs to a format that you can then ship off to whatever else you need next in your pipeline.
Okay, so a little about formatting queries, while I’m in, in this presentation in particular. So this is kind of a rhetorical question.
It’s, it’s based on your, your preferences I guess. So I would say this is okay because I left syntax highlighting in so you can kind of make out the keywords, but it’s just it all one line.
It, it’s very hard to read. Versus over here. These, these are actually the same query. They do the same thing, but they look very different because. So I’ve uppercase all of the keywords which is actually just convention.
So in SQL whitespace and the case of the keywords both don’t matter. You can, you can write select uppercase, which is often you’ll, you’ll see that, but you can also write it lowercase and databases will take that just fine.
you can put in whitespace to, to format the queries to make it easier to read, which I highly recommend doing because as I mentioned before, a hundred long, 100 line plus long queries get a little difficult to read.
so anything that you can do to increase that readability really, really is worthwhile. All right, data exploration, let’s take a look at the data set that we’re going to use for the examples here.
So it’s just a HoneyPot data from 2013. The file name we’re going to be using is Marks Geo CSV. I pulled it from Data Driven Security, Security’s website and a little caveat.
So I did have to do a little bit of data cleaning. so Washington D.C. had a little comma in it and because it’s a CSV, it was messing up, messing up the parsing for DuckDB.
And I’m sure I could have figured out a way to do this processing in DuckDB. But this is just an example where oh hey, quick one liner to pre process my data and then everything Else went great.
So the data itself is a time series. So that means every entry has a timestamp and each entry has information such as like the IP address that we’re dealing with, the host name of the honeypot, the port protocol.
It’s got some geolocation information in there. All right, so what’s the first thing you might want to do? Getting a new data set. Well, let’s try this select star from and then.
Interesting. We’re just pulling from, right from the file. So this is a really cool feature and I’ll talk about this a little more later about DuckDB but it can read straight from files and so this is, this is what our dataset looks like.
We’ve got a table and you can see it’s truncated here. It’s not showing us all the columns, not showing us all the rows, but it’s just a quick, view of what does this data kind of look like.
And I’ll often do that for, with select. Cool thing about DuckDB is it’s truncating for us. But some databases might not do that.
You might get all 451,000 rows scrolling past your screen, which isn’t great. So how do we fix that? Well, we just add on a limit.
We say limit. This is the equivalent to the head command in Linux. except we’d be limiting 10 by default there. so this is going to pull the top, the first eight rows and this is what we got.
I removed some of the columns just for brevity here. So really it’s not. Select star is not what we’re seeing. But, this is kind of what you would see if you ran this in the terminal.
All right, next, what does. So we’ve got an idea of what our columns are, the kind of, the data that’s in them. Let’s, let’s just take a look and make sure we understand all of the columns.
Like this is take a look at the header essentially. So we’re going to use describe and we’re just going to put it right in front of the query that we were just running. And so this is going to tell us how DuckDB is interpreting this data.
So we’ve got a date, time column, host column, proto like, here’s the list of all the columns in our data. And DuckDB does a, it takes a sample of data and it determines what data type fits best.
So it looked at the date, time column and saw. Hey, I can, I can make all these timestamps so it. Go ahead, it Went ahead and made the data type timestamp.
these are. Varchar is another way of saying a string. So there’s a bunch of strings and then there’s a bunch of integers and then the null column is just saying, hey, are there empty, any empty values possible in this?
Like did we, did we see any as we went through? And the answer is yes for all of these. All right, next, this is a very cool feature and so if you recognize this logo, this is the DuckDB’s logo.
So I’m going to put this around. I’m going to, I’m going to put this in when I am demoing a feature that is specific to DuckDB or at least I haven’t seen it in a whole lot of other databases.
So it’s not something that’s going to, you’re going to be able to take this and run in like MySQL for instance. So this summarize command. So like we just did describe in front of our query, now we’re doing summarize in front of our query.
And what that’s doing is honestly it’s kind of a duplicate of describe because we’ve got our column name, we’ve got our column type. I don’t know if it does the null column.
But anyway there’s descriptive statistics about each of these columns which is really cool. So we can automatically see that the min timestamp and the max timestamp we have our, the date range that our data set is from just right here.
we have so host is the name of the honeypot. So we know that for approximate unique, we’ve got 10 ton of honeypots that this dataset covers.
There are three different protocols which we can see two of them here and I bet you you can guess the third one. Tcp, type.
It just shows, yeah, min and max. So this only is going to apply to ICMP traffic, which is why over here the null percentage, most of the, most of the values are actually null for this type, which is interesting, but that’s because it only applies to icmp, which is the minority of the traffic.
We’ve got destination ports and so you can see for all of the numerical fields it computes descriptive statistics like average.
there’s some that I’m not showing here. So you get, you get standard deviation, you get the quantiles, quartiles, you get the count, the number of rows in, in each one which the count is going to be the same for all of these.
But anyway, it’s, it’s a very useful feature just to get a quick overview of your data. All right, so let’s dive into what’s.
What a select query is. So this is, there’s a lot you can do with a select. And this is just the first part. This is, hey, give me the columns. so you can, you can say, hey, I want, I want just a literal value.
So select welcome to the webcast. And that’s it. That’s a valid SQL statement. That’ll just return a string. Welcome to the webcast. You can give it an alias.
So basically you’re assigning a column name to this value that you’re putting in, which you can, which is useful for both displaying on the output. It’s kind of labeling, giving your table a header.
or if you’re, if you need to refer to that data later, you can refer to it with a shorter name or a more descriptive name or something like that if you need to refer to it later in your query.
we saw this form already. So select star. Star just means, hey, give me all the, all the columns. And then from is saying, where am I pulling this data from?
So here I’m just, I’m leaving it off. But in the past example we’re seeing, I was specifying a file. You can choose, you can pick, specific columns by name.
This, is a DuckDB kind of exclusive feature. But you can say select star. But I don’t want these columns. So you can get all of them except for these, columns that have spaces in them are valid.
Those are, those are valid column names. You just have to, you just have to put quotes around them. And double quotes, specifically single, quotes like over here are used for strings.
Double quotes are used for identifier identifiers or sorry, not, not identifiers, but like null would be an identifier if it didn’t have quotes around it.
But I’m putting quotes around it to say, this is a column name. This is the name of the column. you can get the count. And this is a really typical query that it almost belongs more in the data exploration.
But when you start doing data analysis and you start getting results back, you’re like, hey, I wonder how many results there actually are. So a lot of tools will just tell you that outright.
It’ll say how many results were returned. But if it doesn’t, this is a useful query. Just in general. you can, you can do math.
You can addition, extraction, division, you can, you can do a lot of interesting stuff like perform runtime application operations, on the fly, which is really cool because like say in elasticsearch, that’s not, not really something that you can do.
or at least maybe in one of the specialized operation or data visualization types, I don’t know. But but in SQL that’s, that’s really common to do actually.
you can add, add columns to gather, truncate. I mentioned like data cleaning earlier, that’s something that you would do here. Just, hey, I want to, I want to trim off all the white whitespace off my string column or I want to convert my string column into see, see if it, they’re all numbers.
I’m going to convert it to a integer instead. you can use the distinct keyword to see the unique rows that you have. Also very useful.
And those are just a few examples. There’s plenty more I could have put in. Just wanted to show you some of the ones that I found most useful. Okay, so next we’re going to introduce the from clause of the select statement.
So typically in a database, this is, this is what it would look like. And this is valid in DuckDB as well. But you would, you would insert some, some data into a table. So insert into table values.
These are, these are values. And then you would do a select statement you select from table. So you insert into a table select from a table. DuckDB can do that too. DuckDB, goes a little bit further.
So all of this is DuckDB specific. DuckDB lets you just omit the select star. Normally you’d have to put that in, but DuckDB, lets you emit it or even put it after just because the first thing you think about is from like hey, where’s my data coming from?
And then you start thinking about oh, what, what do I want to pull out of that data? And we’ll, we’ll cover that a little bit, on a slide as well. So DuckDB as you, you’ve already seen this form, we’re reading from a file and I just passed it a string and it auto detected that it was a CSV and it’s doing that because of the file extension.
So if you’ve got a different file extension or you need to give it specific parameters. hey, my delimiter isn’t a comma, it’s a tab or it’s a pipe or my data is quoted or not quoted.
And if DuckDB doesn’t automatically detect that they have a function. So these Two right now just equivalent. but the function has a bunch of other, you can see one example here, parameters that you can give it to tune how it’s going to interpret your data.
And CSV is just one example. They’ve got, there’s JSON, there’s I think avro parquet, several other types of data that you might encounter that you can just read straight, straight from the files.
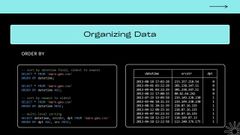
All right, so once we’ve got our data we might want to organize it. This is equivalent to sorting and we do that with the order by clause. So pretty pretty straightforward. We’re still selecting everything from our file and let’s sort it by date, time and these are actually doing the same thing.
So even though I’ve got ASC here, so it’s shorts stands for ascending. So we’re sorting in ascending order. That’s the default. So if you leave it off you’re going to get ascending order.
actually this, this one is, this output is for the one down here opposite of ascending. You can do descending order. So you can say I want newest, oldest, I want the, the greatest timestamp first down to the smallest timestamp.
you don’t have to just sort by timestamp either. As we can see down here you can sort by any column. So here we’re sorting by the destination port first, ascending order and then the source IP address or IP equivalent.
I think this is the integer equivalent, in descending order. So what this shows is something I think is really cool is multi level sorting.
So this is something that you would struggle to do in bash Kung Fu command line Kung Fu. I mean there is a way to do it. There are like the dash K flag to the sort command.
But it’s just kind of clunky here you just say hey, I want to sort by this column first and then within this column anything that’s equal we’re going to sort in descending order by this one next. So you can see that.
So we’re sorting by destination port and then within that we’ve got source, source IP addresses going from largest down to smallest.
Sorting I would also often pair with limit, the limit clause. So that would be a quick way to get hey, what’s the top 10? What are the top 10 or the first 10 or the last 10 or something like that.
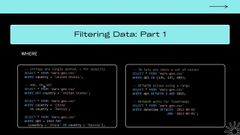
If you’re, if you’re just trying to get the tail ends of your data. So how would we filter data? We would use the where clause and we can just say hey, the Column that I’m concerned about is country in this case.
And we’re just saying select all, all columns from my file. Where the country value. The value in the country column is equal to the string United States.
So that’s going to pull all the, all the results. Where countries United States. The where clause can get pretty, pretty long and complicated. You can string a lot of stuff together.
And the way you would string things together is using Boolean operators and or not boolean logic. So this is one way you could invert the condition.
You could say where not country equals United States for equality. You could also just say we’re country not equal to let you put a little exclamation mark here.
Equal to United States, but not as useful when you get. When you want to invert like a whole string of Boolean operations conditions together. Like down here we could say and not.
And then it would invert this whole thing in parentheses. So you can combine. This is how you combine with or. So country equals China or country equals Russia.
And then remember, order of operations. So if you haven’t encountered that before and has a higher precedence than or. So if you didn’t have parentheses here, you would, you would be looking for destination port 1433 only from China or everything from Russia.
That’s, that’s what it would return without the parentheses. By putting parentheses in, we’re forcing, hey, I want this port from either of these countries, but only, but only if it’s this port.
And this is actually a really common mistake that I’ve seen people do is they forget to put parentheses around the OR and then they run their query. And either it takes way too long because you’re in a crazy data set and you’ve just put on a global or a condition that is going to return way too much data, or you just get junk data back.
Like, and you have to figure out, why, why isn’t this filtering what I wanted it to. So another, another keyword is in. So you can say, you, want a value in.
And then you could say a set of ones. So this would be equivalent saying, hey, I want destination port, equals 133 or destination port equals 137 or destination port equals 445.
This is a much shorter way to write that. You can do a range. So any, anything that can. I think this would work for, for anything. it’s less intuitive when you’re working with like strings, but it definitely, makes sense for numbers.
So be quick between 1 and 1025. So any, any numbers that fall between like 1 inclusive or 1025 exclusive, so up to 1024, you would return in this case.
And the cool thing is this range, this between works for date timestamps as well. So here, like we’re using single quotes, this is a string.
But DuckDB is smart enough to know, hey, the column type for datetime is a timestamp and it can convert this, it can typecast this implicitly to a timestamp.
And same with this. So it just does the range then between the two timestamps, which is pretty cool. All right, aggregating data we’ve saw, we’ve seen count already.
There are tons of aggregate functions, dozens I would say. you’d have to look at the website to get a list of them all, but there’s some, the common ones, like, hey, let’s get the minimum value, let’s get the maximum value.
There’s average standard deviation. I mean a lot of the ones that we saw in the summarize command, you could call those individually, but there’s tons and tons more. if, especially if you’re needing a special, needing it for a special use case, you can get the number of unique values.
Do weird, statistical calculations, kurtosis, skew might have been one of them. So this, this is pretty simple.
All we did was just called the function and we haven’t done anything else yet. But you’ll see this is actually a special case. So if we try that, let’s say we wanted to, Oh, sorry, going, back to this one, this is going to get us the minimum and the maximum values of the entire data set.
So notice when we run this we get one result back. So that’s another key thing about aggregating data. you get fewer results at the end, typically because it’s going to condense down a bunch of rows into a single, single metric.
So what we can do, what if we wanted to not get the count for the entire data set, but the count per honey pot host that we’re dealing with, we might try to modify our previous query and just say, hey, I want the host in there too and give me the count.
This is going to give an error. And this is our first introduction to what DuckDB errors might look like. So this is a really, actually there’s a really good error because it describes exactly what went wrong and how to fix it.
And then it even points like here’s the problem here, an arrow. So the column host must appear in the group by clause. Hey, we don’t have a group by clause. All right, well, maybe we need to add one.
Or it must be part of an aggregate function. Well, we don’t have an aggregate function around our, our host, column either. So either add it to the group by list.
Yep. Or we can, and then it’s suggesting an aggregate function. It’s just the, any, any value aggregate function. but that’s, this is what we want to do. We want to add it to our group by list.
So what does that look like? So this is, this is the one that we try that give an error. And here’s how we fix it. With the, group by clause, we add group by host.
So this is breaking up the data set by host. So for each individual host value that we get each unique value, it’s counting how many there are.
So this is hopefully where you can start to see some of the power of SQL. aggregations is kind of the first, really.
Aha. Huh. Like, yes, this is. I have all the power. All right, so what, why, why did it give an error before? What, what was happening? So I mentioned with our original query that worked, this one worked.
It’s because there’s actually, there’s an implicit groupbyall, feature or implicit groupbyall, clause here that you don’t need to put on there.
So if all of the columns are in aggregate functions, it’s just doing this. It’s saying group by and then all values.
And in, this case it’s just the entire data set. All right, so we got our results and we had the count of records per host.
What if we wanted to trim that list down? Maybe we got more results than we wanted and we want to get. We only care about the ones where the number of results is greater than a hundred thousand.
How would we do that? Well, we’ve already, we’ve already seen the where clause. So let’s try that. We, we know that’s for filtering data and we try that and we get an error.
And if we look there, it says the where clause cannot contain aggregates. Well, there’s what, where’s the aggregate? I don’t see it. Well, it’s because we’re aliasing the aggregate, so we’re saying count.
And CNT is a very common abbreviation for count in SQL just because if you wrote out the word count, it would conflict, with the function.
It would typically work still, but it’s just, it’s more confusing and it could cause an error to crop up. So CNT is short for count.
So we’re assigning count to an alias called cnt and then we’re using it here. So that’s why it says we, you can’t have an aggregate in there because it’s just aliasing Count the aggregate function into our where clause.
And it doesn’t like that. So what do we do instead? Well there’s a having clause. So select host, we want our host and count as count from our data set.
We’re doing group by all. So we could actually do group by host here instead and just specifically put our host here. but all is just a shortcut again for give me all of the individual values that are specified.
And then we’re saying halving. So we’re just taking what we had put in the where and we’re doing it in the having clause instead. So this is just a way of filtering after the group by, after the aggregate operation, then we get our result.
So why do we have, why do we have this? Why do we have the where and having. And why is select first but from. But. But we think about from first.
It’s, it’s kind of confusing. So there is a difference between how you have to write a SQL query. And remember I, I mentioned at the beginning, SQL can be kind of clunky.
This is one of those things that it’s like, yeah, it’s kind of clunky. There are tools out there and projects out there aiming to fix this kind of thing. But it’s, it’s just, it’s where we’re at.
So the structure of a SQL query is set like you have to have select first from comes after select join. Like they have to appear in this order. You don’t need all of these.
As you can see, we haven’t, we haven’t even introduced a lot of these yet. But if they’re optional, they you can omit them, but they still have to appear in this order.
But the order of execution is actually over here. So if we look, we’ve got our from, we’re reading from our table and then we’re filtering data out using the where clause and then we’re doing our group by hmm.
And our aggregation happens with the group by. And then we’ve got our having clause. So if you think about our last example, why, why couldn’t we use the where to filter on our aggregate?
Well, it’s because by the time the where step happens, the aggregate hasn’t been commuted yet. That, that only happens after the where is, is, processed.
So that’s why there’s an extra step here in order to give you the additional ability to filter, after an aggregation.
All right, so now we’re going to get into some fun stuff and I’m gonna have to rush through a little bit more than I wanted to here. I’ll get through window functions and then we’re going to just very briefly touch on join, joining.
So, window functions, we’ve already introduced aggregates. So aggregates takes your data and condenses it down. It takes all your rows and it computes a sum, for instance, and you get one result at the, at the end, one result per group.
but it, but it’s condensing the number of rows. Window functions, they also use aggregate functions. You can use sum in a window function as a window function, but it’s not going to condense the number of rows that you end up with.
You keep. For every row that you start with, you still have that row in your output. You just have an additional column with a sum over some other set of, rows.
So really cool thing that you can do with this, several cool things. You can, you can keep a running total. You can say, hey, if you’re ordering your data set, we’ll see that one next.
I’ll, I’ll cover it. Then you can have a rolling average where previous entries will fall off as, as you get a step forward in time, you can calculate a percentage of the whole.
Like for this particular host, how many, like what percentage of the entire data set does this particular host comprise of? we already talked about limit where you can get, hey, that you can get the top 10.
So if you sort your data set and you say limit 10, you get the top 10 results. But what if you want to say, I want the top 10 results per host. Well, that, that.
There’s no obvious way to do that. So how you do that is with a, window function, you get top values per group. So what does a window function look like? The syntax is a little more complex than what we’ve seen so far, but the main thing is look for the over keyword.
So over shows that, hey, this is a window function, not an aggregate function, because it’s the same like sum, we’re using sum. So if we didn’t have all this junk, we’d just be doing an aggregate and we’d need a group by, or there’d be an implicit group by.
But here we’re saying over and then we specify what are we Summing over. Well, we’re partitioning by hosting in this case, so that’s kind of equivalent to our group by.
So we’re just, we’re segmenting our data out per unique value in the host column. You can order those, those rows within, within your partition and then you can specify a frame clause which tells you, tells how many rows basically to compute the sum over.
So the very basic level, you could say, hey, I want it to compute over all the entire data set. And you can do that, you can do that with a frame unbounded preceding and unbounded following.
Just say all the way to the beginning, all the way to the end computes over the entire data set. In this case we are doing rows between unbounding preceding. So all the way to the beginning of the data set and the current row.
So for every row that it does, it processes, it’s going to go back to every row that went before it, sum all those up and it’ll stop at the current row. And then this is how we get a running total which we’ll see in the next, next slide.
This is just the syntax like the, for the frame clause specifically. It looks a little hairy. It’s, it’s not all that bad. basically you have your option between range and rows.
We saw rows already. That’s, that’s what we’re going to cover in the examples here we’ve got between, and I mentioned unbounded preceding and unbounded following.
That’s one of the examples. current current row is in there. You can spit that in there. there’s, there’s some other special cases you can leave off like one or the other. But anyway, I won’t cover all the examples because as you can see there’s a lot of different branches that you can follow through here.
Which just goes to show that it’s, it’s pretty powerful tool. Okay, so let’s look at a running total. So we’ve got sum over per host partition by host and we’re ordering by date time.
So with our results, we’ve got blue is one value, it’s Oregon. We’ve got pink is Tokyo and then black is Singapore.
So if we look, we’ve got 6,000. Well, this is our first result for. I’m adding the source port. Don’t think too hard about why we’re adding the source ports. It’s just for an example.
the first result we got 6,000 because that’s it, that’s our only data point at this point. So if we go down to our next row, we’re adding in 5,000 to our previous total.
So we get 11,000 here, we’re adding in 2,000 to our previous total. So really, when it’s going through, it’s just, it’s adding up all of these as it goes.
And so then we get a running total in this column. And notice here we’re adding 56,000. Well, it doesn’t add it to the 13,000 because this is a different host, a different partition that we’re working on.
So it starts a new running total for this value. And you can see it does the same thing for Tokyo. We’re starting a new running total here. And then we’re continuing for Oregon.
So we’ve got 13,000. Before we’re adding 6,000, we got 19,000. So we get a running total per whatever you decide to break up your data in.
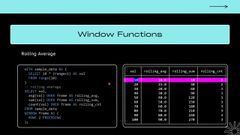
So how would we do a rolling average? So this, this is a little more complex query. you can ignore this part up here. This is just me creating some sample data, for us to, for us to select from, just for illustration purposes.
In addition to doing a rolling average, I’m also going to do the count and the sum, the sum and the count so that we can see more easily. Like how did that average get calculated?
So again, the first value, we’ve got 10. So yeah, our value is going down, just counting by tens, all the way down to 100. our sum is 10 because it’s the first result. And our count is one because we’ve only, we’ve only had one record so far.
So our average is 10, 10 divided by one 10. Next we’ve got 10. And 20 is our frame that we’re processing. And there’s two records in that frame.
So our count is two and the sum of them is 30. So the average is 30 divided by two 15 going down again. Now our frame has three records and our average is 20.
Our, total is, was 60. It was just 10 plus 20 plus 30. All right, so next step is where something interesting happens, the frame shifts. Because if we look at how our frame is specified here.
Oh, and that’s the other thing I didn’t mention. So because I’m specifying this frame multiple times, SQL actually has a way where you can specify it once at the bottom so you don’t have to like, duplicate it.
So just think of this as what we were doing before, just kind of as an alias, like setting a variable almost and putting it in here.
So we’re going over the two preceding rows and the current row. So current row isn’t listed here, but that’s, that’s the default.
So with, our next step, we’ve got three rows. So 2. We’ve got the current row and the two preceding ones. So our frame is 3. Notice how it doesn’t change going down.
It’s. It’s always going to stick at three once it, once it fills that frame. So at first we don’t have three, but once, once we processed enough to fill that frame, then it stays the same till the end. But our sum keeps changing because we’re adding different numbers in that frame.
So 20, 30, 40 is 90 and divided by three is 30. We got 30, 40, 50 is 100, 20, 40, 50, 60, 150.
So you can see as we, as, as it goes through calculating the window functions, it’s shifting that frame, down within your window. All right, so another example, this one is the most simple to write out because the window function is empty.
Notice our over keyword that there’s. There’s nothing, there’s nothing specified there. But it’s, it’s really hairy to think through and explain. And I’m not, I don’t have time to go through it.
but this is how you would calculate a percentage of a whole. So what you get is, we’re doing, if you think about this, we’ve got count is x times 100%, just so that we are not dealing with fractions, divided by the sum.
So we’ve got the number divided by the total. And that’s how you get the percentage. Right, Your portion divided by the total is the percentage when you.
And then you multiply by 100. So we get 42% here. so in this case, the number of connections that came from China made up 42% of the data set.
Number of connections that came From United States, 19% of the data set. All right, so what if we wanted to filter using window function?
Well, should we try the where clause? I don’t think that will work because it didn’t work for aggregations. And, indeed we get an error. All right, so let’s try having.
No, we. We still get an error. Okay, well, how do we, how do we filter window functions? Well, it’s not pretty. This is how you would typically do it in a, In a.
Most databases, you, you can write this as a subquery or how I’ve gotten written. Got it written here is a common, table expression or cte, where you just basically say, hey, I’m defining a query up here.
I’m writing another query that goes that queries from that query. So it’s like a nested query and then, and then we can use where. Because this happens first.
But luckily DuckDB has an answer to this. they introduced the qualify statement which is just so that you don’t have to write that big long query.
But, but this accomplishes the same thing. It’s just, it happens after the window functions are computed in our, in our order of operations earlier.
All right, so now we get into joining data. So joining is a fairly complex talking topic as well. But I’ll just kind of give you an overview and show you what kind of things that you could accomplish joining.
So you could enrich a table. You could say you have a data set and you want to, and then you’ve got another CSV or something with max plan information or geolocation information and you want to add that into your original data.
You could use a join to do that. So it was kind of acting as a lookup table at that point. And in this case you’d end up with probably the same number of rows as you started with.
You’re just enriching your current data with adding, adding some additional columns. Joining can also be used as a sort of filtering. You, you can. So we filtered several ways already.
But if we didn’t know what our condition was like, say we didn’t know, hey, we want count less than 100 or count greater than a hundred or something. What if, what if the data that we wanted to filter by was located in another table?
You could use a join to basically dynamically filter your data based on data that’s in a different table. And in that case you’d end up with probably fewer results than you started with.
And likewise on the flip side, you could expand the number of results you have by doing like, like a Cartesian product or a combination of all the different values in both data sets.
I don’t see that used quite as often but, but it is definitely possible I, I should retract that. I do see it used but it’s almost always unintentional.
It’s usually because of a mistake in your join. All right, so types of joins that you can use. there’s the classic inner join, there’s outer join of which there are three different subtypes, there’s a cross join, and then there’s several self, special purpose joins that are really interesting and useful.
but we’re not gonna. We’re not gonna get into those. And those can vary per database. But almost any database you work with is gonna have these three inner, outer and cross. So a lot of times people explain joins with Venn diagrams like this, and they do make a certain sort of sense, but they can also lead to some confusion.
so there’s another way to explain joins that I’m going to try here with this image. Got a couple minutes. We knew it. So an inner join is going to look at, Okay, let me talk about what it’s showing here.
So we got two different tables, on the left and on the right. And don’t worry about the 1, 2, 3, ABC. That’s just showing which table it’s in. The colors show that the values are matching.
So the blue. The blue squares match the yellow square or the white squares match. The black square doesn’t have a match in the other table. The orange square doesn’t have a match over here in this table.
So an inner join is going to return rows where there’s a match in both tables and notice what’s missing. Well, it’s the ones that were not common between the tables.
So outer join is going to. Oh, did I hear something?
Jason Blanchard
Hi, Ethan.
Ethan Robish
Hi.
Jason Blanchard
Hey. We’re at the top of the hour, but I want you to keep going.
Ethan Robish
Okay.
Jason Blanchard
just knowing that the recording will be available for anyone that has to leave.
Ethan Robish
Got it.
Jason Blanchard
And I don’t want to stop you. Cause you’re on a roll.
Ethan Robish
Yeah, I have just a handful of slides left. Yep. I’ll, I’ll speed through.
Jason Blanchard
No, no, don’t speed through. Just do what you gotta do.
Ethan Robish
Left, left join. We get the same two in common rows that we got before, but we also get the data that was unique to the left table, the table on the left side. That’s why it’s called the left join.
So we’ve got, we’ve got this black one here. Right join is opposite. Except we’ve got the one that was on the right side, the column or row, the row that was on the right side.
And then a full join gives you both. So it’s going to basically merge your data together. Full outer join is going to merge your data. You get all of your original on the left, all of your original on the right.
And then anything in common is just. It’s going to be in the same row. So where your data matches. you’ll get that as well.
All right, so here’s an example. And this would be an example. The first Use case I gave of enriching data. So let’s say I’ve got a second data set. So we’ve got our first data set marks geo that we’ve been working with so far.
And then I pulled a second data set just from iana’s website about port common ports and what services run on those ports. And let’s say I want to join these together, see like hey, what, what’s the explanation of this port?
Like we’ve got destination ports in our original data set, but I don’t know what that means necessarily. I might have to go look it up, Google it for every single one and I want to have to do that. So let’s, let’s join the data together.
So we’ve got our select statement as we’ve seen so far. Got a little bit of extra with this marks.in a. I’ll touch on that in a second from our original data set.
And notice I’m giving our original dataset an alias with the as keyword. So this basically marks means original dataset.
Doing the same thing over here. IANA means our new like data that we’re going to be enriching using to enrich and so, so we’re doing a left join.
So this is going to be a left outer join technically. So outer I mentioned on the last slide it was it’s an optional keyword. If you use left, right or full, it’s assumed to be an outer join.
and if you just say join it’s assumed to be an inner join but you can also say left outer join and that means we’re going to get all the data from our left data set here, just with additional information from our right data set.
And what are we joining? So we’re joining where the protocol from the marks table, is the same as the transport protocol column from the INA table. So notice in these data sets the columns are named differently, the values represent the same thing but, but, but even then the values like in this case it was up these, it was like tcp, udp, icmp, that’s what is talking about the transfer protocol or probably TCP and udp.
Just in this case, they were uppercase no, sorry, they were lowercase over here they were uppercase stored in our original table. So in order to get them to match I actually had to do some processing.
So lower, lowercase it and then we also want the port number to match. So again I actually had to typecast as a string to get it to match what the data type was being detected as in the IANA data set.
But basically matching port between the two and sorry, protocol between the two and then port between the two and over here we can see the result. We’ve got our ICMP which is from our left table.
But there’s no, there’s no information. Well it’s because it’s just ICMP is there’s no common port or anything that service running on that port. So we still have all our original data.
but then where there are values they’re filled in for the service. So for each common port. So like 143 we now know that that’s IMAP and that stands for Internet Message Access Protocol.
Just one example what you can use join for. As I said it’s a pretty in depth topic. lots of use cases there. But hopefully this gives you kind of a taste of what’s possible.
So I wanted to thank you and end with like a holiday themed topical joke. but yeah we can end here, go over any questions.
I appreciate everyone’s attention and attendance.
Jason Blanchard
Well done, Ethan.
Deb Wigley
Fine.
Jason Blanchard
Well, how’s my mic? Everything sound okay?
Deb Wigley
It’s better now.
Jason Blanchard
Okay, so for those of you that are sticking around, if you did not get your questions answered, please ask again just to make sure that we got it and also that you’re still here.
so that way, and someone said cute SQL query, so I think someone got the joke. Ethan.
Ethan Robish
Yes, I did not come up with it. I tried to find the original source and it was a, a rabbit trail of Twitter posts leading to accounts that were not around anymore.
So I don’t know who originally came up with it.
Jason Blanchard
while we’re looking for questions, reminder, if you have not checked in for Hacket, please do so. It’s a manual process for us to go through and update your things. If you don’t know what Hacket is, it’s inside Discord, the Black Hills Discord server.
And we’re in the live Cast chat and select the Ethan chat. and so if this was your first time doing that today, thank you so much for doing it. And then if you’re in Discord and you’re in the chat, let us know what you thought of the format.
Like was it too difficult to find how to use it? Did you have any problems with it? we’re gonna try it two or three more times and if it doesn’t work out then we’ll go back to doing it the Old way.
Deb Wigley
Kelly had a great suggestion. She said just to put in the announcements kind of the little video that HK made so people have a little bit more, information before they show up here.
there is one question for even, what are the essential distance between SQL and Oracle database and which one is best for data analytics?
Ethan Robish
Sorry, differences between SQL and Oracle. so Oracle would be a database that uses SQL to access it.
Oracle is going to have its own flavor of SQL. if you’re talking about like DuckDB versus Oracle. So Oracle, I want to say that’s going to be a transactional database, but I don’t actually know.
I know it’s a, it’s a monster. if you have Oracle, you’re probably using it for everything.
Jason Blanchard
I think that’s all the questions.
Deb Wigley
I think you answered all of them during it. Yeah, well done, Ethan.
Jason Blanchard
did you already ask that one about where to graph database like Neo4j fit in with the OTL?
Ethan Robish
Oh, right. So I originally had a third category on that slide, for NoSQL databases essentially. So it’s a broad blanket term.
NoSQL just means, hey, this database doesn’t use SQL to access it. Some graph based databases actually do use SQL to access it. So yeah, graph, I also mentioned there was different ways you can categorize databases.
It’s not just like, oh, it’s analytical or transactional, like there’s other buckets you could throw them M in and being a graph database, is one of those buckets and that would typically be a NoSQL database, but not necessarily.
Jason Blanchard
All right, all right, Ethan, so what we normally do at the end of a webcast is we ask you to think about your final thoughts. If you could summarize everything from today and one final thought, what would it be?
So what is that?
Ethan Robish
M. You should have prepped me for that. Sorry. SQL is a powerful, tool and hopefully this gave you an idea of whether it would be worth adding it to your arsenal.
And hopefully it introduced you to a specific tool called DuckDB, that you can maybe use to help with your workflow, especially if it involves data analytics.
Jason Blanchard
I got one more question for you. It’s a question, I want to know how difficult is it for you to come up with an intro level webcast when it so well?
Like how do you make it an intro webcast?
Ethan Robish
I mean, did I succeed? Is this an intro webcast?
Jason Blanchard
I think that’s a good question. did this feel like an intro webcast to the people Watching.
Ethan Robish
I mean, I definitely started with the basics of the SQL query, but then I jumped directly into something I would consider advanced into window functions. But I did that.
I know I did that on purpose, though, because I wanted people who were interested in SQL and knew the basics already to come out with something that they probably haven’t heard of. I’ve talked to a bunch of people that are very well versed and know, like, computer scientists have interacted with databases.
didn’t know what Windows functions were or how useful they were.
Jason Blanchard
It looked like it was an intro webcast based on the people listening. Cool. Well done. as I wrap up. Thank you so much.
had a burp, but it didn’t come out. Then I was like, should I mention it? And then I did all the things, so. So next week is Thanksgiving. We will not be here next week unless you’re watching the recording.
The next week is not Thanksgiving. if this is still a part of the recording. but, we have the Secure Code Summit coming up on December 4th, so make sure to sign up for that. That’s totally free.
But then there’s two days of paid training right afterwards. And then, we had a couple more weeks before Christmas in, In New York New Year, so please join us on Thursdays. And if you like the new format, being able to go in and then being able to go back to the previous webcast where find the resources, the questions, that were asked, links, the answers that were given, let us know.
we’re going to do this a couple more times, and if it works, then wait till you see what we plan in 2025. All right, Deb, any final thoughts before we go?
Deb Wigley
no, we’ll miss you guys next week. but we’ll be back at the following. but yeah, Happy Thanksgiving to all who celebrate Turkey Day.
Jason Blanchard
All right. All right. Ryan, kill it. Kill the fire, Ryan. Kill it.