
Adversary in the Middle (AitM): Post-Exploitation

This webcast was originally broadcast on October 24, 2024.
In this video, Michael Allen discusses adversary-in-the-middle post-exploitation techniques and processes. He explains how his team at Black Hills Information Security conducts continuous penetration testing to find vulnerabilities and improve security. The session covers practical steps attackers take post-exploitation, how to defend against these attacks, and the importance of persistent testing to identify and remediate security gaps effectively.
- The webinar focused on post-exploitation strategies following adversary-in-the-middle attacks, specifically targeting single sign-on portals to gain access and maintain persistence.
- One of the main strategies discussed was creating email rules to prevent users from being alerted to suspicious activity, thereby maintaining stealth within the compromised accounts.
- Social engineering, particularly through phishing and manipulating help desks, was emphasized as a critical component of gaining and maintaining access during penetration tests.
Highlights

Preventing User Alerts on Suspicious Account Activities
Discusses how to prevent users from receiving alerts about suspicious account activities by blocking related emails.

Operational Security Tips for Managing Multifactor Authentication Alerts
Avoid push notifications to prevent alerts, minimize sign-ins, and reset MFA methods to maintain operational security.
Chatbot-Assisted Multifactor Authentication Setup
A customer used a friendly chatbot to reset a multifactor token, despite usual rules against resetting, while user was out.

Exploiting Single Sign-On: Navigating Internal Networks
Guide to accessing internal networks through single sign-on, using web-based remote desktop services without multifactor authentication.
Using Firefox Tab Reloader to Maintain Active Sessions
Learn how to use a Firefox extension to keep web application sessions active by automatically reloading tabs periodically.

Understanding Device Code Authentication in Microsoft Services
Explore how device code authentication works in Microsoft services, allowing smart devices to access accounts seamlessly and securely.

Strategies to Mitigate Adversary in the Middle Attacks
Learn how to defend against adversary in the middle attacks using multifactor authentication and restricted network access strategies.

Optimizing Post-Exploitation Security Measures
Configure session expirations for single sign-on portals and restrict remote access to enhance security against potential threats.

The Future of Compliance: Continuous Pen Testing and Regulatory Shifts
Continuous pen testing is essential for compliance, anticipating future regulations requiring ongoing security evaluations for organizations.
Full Video
Transcript
Jason Blanchard
Hello, everybody, and welcome to today’s Black Hills Information Security webcast. My name is Jason Blanchard. I’m the content community director here at Black Hills Information Security. If you ever need a red Team pen test thread hunts active sock antisoc, where to find us.
We are here to help you improve your security. And especially Michael is going to do that today. So Michael gets a, he’s in our continuous pen testing team. Essentially, you get to think about just hacking people all day long.
Like you’re the friendly apt, you get to be a, client’s apt, come up with the thing, things that you can think of of like novel ways to hack organizations.
And so today’s presentation is like some of the stuff that you get to do, right?
Michael Allen
Yeah, it is, yeah, yeah. This actually, all this information today is coming straight off of the antisoc continuous pen testing team.
Jason Blanchard
Awesome. And this is like the thing that brings you joy, right?
Michael Allen
I mean, it’s a thing that brings me joy.
Jason Blanchard
All right, so if you don’t know how webcasts start or happen here at Black Hills, we normally ask the people on the team, hey, would you like to share your knowledge? And they say, like, on what? And I’m like, what excites you? What makes you happy?
What brings you joy? and so this is a topic that at the time brought Michael joy, and so he’s going to share it with you today. And so if you have any questions whatsoever, feel free to ask them in zoom. If you have comments, questions, or anything else that you, you can also share it in discord, and your fellow attendee may be able to answer your question before Michael ever gets a chance to get to it.
And with that, I am heading backstage. It’s all yours, Mike.
Michael Allen
All right, sounds good. Thanks, Jason. All right, everybody. Welcome to today’s webcast Adversary in the Middle Post Exploitation.
as Jason said, my name is Michael Allen. I am a Red Team practice lead at BHIS, and I’m also an initial access specialist on BHIS’s antisoc continuous pen testing team, which is pretty much my primary, role at the moment.
All the testing that I’m doing at the moment has been on our, continuous pen testing team. And on that team, I am responsible for, coming up with attacks and launching attacks that get us initial access into a variety of well defended customer environments.
So because of that, specialty and that special focus, I also teach a class that is Red Team Initial Access that, I teach live at any conference where they’ll let me teach it and also through Anti siphon on demand.
So I’ve got links in the slides there. A couple of live instances that are coming up are in Denver in February of next year at Wild West Hack and Fest Mile high and at KernelCon in Omaha in April of next year.
Also got a couple of links there to my social media accounts, GitHub X and LinkedIn. if you’re interested in the content that I’m going over today, feel free to follow me. I post tools and other resources from time to time that are related to initial access methods and just other stuff that I use in my role at bhis.
So with that I’ll stop talking about myself and we’ll get into today’s content. so as I said in the title, this is all about post exploitation today.
So there is a bit of backstory that comes before the stuff I’m going to be talking about today. at this point in our story we have successfully executed an adversary in the middle phishing campaign against a target organization’s single sign on portal and we’ve captured credentials through that attack.
We’ve also captured the session token of the user who signed into our portal and we’ve then successfully hijacked that user session on the single sign on portal. So now we have access to that single sign on portal.
And all this stuff that I’m talking about in today’s presentation, this actually came from it was the result of a massive adversary in the middle phishing campaign that we did on the continuous pen testing anti soc team against many of our customers all at once.
We did the, it’s a postcard phishing attack that I’ve actually got a link to it on the last slide of this deck that I’ve talked about in a previous webcast. But we had so much success that we were not, we’re not expecting that level of success that it was just all hands on deck trying to get all testers to take over these accounts that we had now got access to and triage all of those accounts to stay covert in the environment to maintain persistent access to those accounts and to start using those accounts to access other things that we could then leverage to accomplish our goals in the environments.
all very quickly and with testers who have different sets of skills. Not all of us are versed in the same tools and the adversary in the middle attack and things like that. So that’s where this is all coming from today.
And that’s we’re going to start. So we’re starting with post exploitation and this is the process that came from that experience all kind of boiled down here on this one slide.
So our adversary in the middle post exploitation triage process that we built from this experience to allow us to as quickly as possible, do the right things and make use of the access that we get from adversary in the middle attacks, and do that quickly and make it a repeatable process across multiple testers.
So to go through these one by one, first thing we’re going to do is prevent user alerts. So again we try and stay stealthy. Then the second thing we’ll do is try and add our own multifactor token to the user’s account that we’ve compromised.
This gives us persistence, at least one method of persistence. If our session in the single sign on portal times out. It also gives us the ability to log into non web resources, for example the vpn.
And then the third thing we’re going to do is to check for internal network access. An important thing to note here is that we can check for network access. We might be able to get internal network access even if we haven’t got our own multifactor token on the account.
I think this is something that discourages a good number of testers from adversary in the middle. Phishing as an attack path is the belief that you’re not going to get access to the internal network through this type of attack, and you’re only going to have access to say a web portal.
That’s just not true. And even if we didn’t add our own multifactor token to the account, we can still get internal network access through a few methods that I’ll show. So another thing I’d like to point out here is that every step in this process is independent of all the other steps that are in the process.
So I, as I said step three, we can check for internal network access even if we weren’t able to add our own multifactor token to the account. We can do any other step independent of the others as well.
We can access and persist in other web apps if we weren’t able to do any of the previous steps or whatever. These are just laid out in this order for maximum effectiveness and to get the best return on the actions that we’re doing.
So we want to stay covert. That’s why we’re starting with preventing user alerts, and then from there on we want to do the action that we can do as quickly as possible that gets us the maximum amount of access that we can get from doing any given action.
So we make the best use of our time. So continuing with the list, number four, we’re going to access and persist in other web apps. And then number five, we’re going to use device code access to access Microsoft services and resources.
Although we’ll have to do that with a bit of caution since there are some, things that defenders can do to kind of prevent that or detect us when we’re doing that. So now I’ll dig into each of these and we’ll talk about each of them in more detail.
So the first preventing user alerts, you’ve probably seen an alert like the one on the left here. In particular, when you log into an account, maybe it’s your email account, your work account, whatever, from a new device, a new browser, from a new IP address, you’ll, often get an email that says there was a new log into your account and it’s got information in there such as the IP address you logged in from, the location you logged in from, the device type that you logged in from, and the browser often is in there as well.
So all of that is information that could let the end user learn that we are doing actions on this account that are not something they’re doing and are, therefore, reasons for them to report this to security that something suspicious is happening.
Another example is on the right, where we’re enrolling a new multifactor token in the user’s account. And we get very similar information in this alert, that, would include all those things that the other alert could potentially include, location, IP address, all of that.
and this is one in particular that we don’t want the user to receive. Because the next step, number two in our process, is we’re going to add a multifactor token to the user’s account, hopefully. So we want to prevent any alerts related to that as all, since that’s, if we can, since that’s part of our plan.
So how do we stop this? Well, it’s really simple. All we do is we create an email rule that blocks, all of those emails that have any kind of, text in them that indicates that, there’s a suspicious login or suspicious multifactor was added to the account or something like that.
So this, this screen here this slide is actually the exact images that I always reference whenever I’m doing this step so that I can look back and see, what was it that I did, what was the exact phrases that I uses for this rule and everything like that.
So first thing I do when I get access to a user’s account is I go into their email, I add this rule to the list of rules and I give it the parameters of the subject or body includes and then all those strings you see there, security alert, new sign, new sign in, et cetera, every, every different variation that I can think of of like a phrase that would be specific to one of those alerts.
The other settings I want to set on the rule are that the rule rule will take the action of deleting the email and it will also mark it as red. So what that does is whenever the email comes in, it lands in the user’s inbox.
Instead of sitting there in the inbox it automatically gets moved to the user’s deleted items or trash folder. And that’s important because since I’m a red teamer, I don’t want to actually delete the email in case maybe I catch some legitimate email that’s not related to my activity with this rule.
So while I’m monitoring their deleted items folder, if I see something that’s generated that this rule catches that is not something that was caused by my own activity, then I can move it back to their inbox, I can mark it as unread and I won’t interrupt anything that that user is actually doing or that’s like legitimate business email.
If I was a real world attacker, I would set that to permanently delete instead of delete and that would just delete it outright and not move it to the deleted items folder or anything like that.
Then the last step is the stop processing more rules to check that box and to uncheck run rule now. So what I want to do is I want this to be the first rule in the list of rules that the user has configured in case they’ve got other email rules configured in there and it being the first rule in that list, if it matches one of these strings in the email, I don’t want any other rules to run on that email and then possibly undo something that my rule did.
So I stopped processing more rules and I uncheck run rule now so that it doesn’t have any effect on emails that are already in their inbox or in some other folder. In their mail. So that way I’m not causing any kind of problems.
I’m not deleting any emails that were important to them or just really doing anything that they would notice and would be suspicious and an indicator of malicious activity in their account.
So once I’ve created that email rule, the next thing to do is then number two, add my own multifactor token to the user’s account. And a really interesting thing that we learned from doing post exploitation on so many different accounts and environments was that by default Microsoft 365 Okta and other single sign on portals do not require you to reauthenticate once you’re logged into the user’s account with an existing multifactor token to add a second multifactor token to the account.
So if I click on one of these buttons that I’ve got noted here, in red and I try and add a multifactor token to the user’s account, I do not get by default a prompt that says okay, put in your username, put in your password and then authenticate with multifactor token.
Before I add the multifactor token to the account, I can just add a multifactor token to the account. So this is actually a huge vulnerability that is exists in the default settings in many single sign on portals.
And if we find this configuration to be the case whenever we’re doing post exploitation in a customer’s environment we call this out as a finding because we are able to add our own multifactor token and that gives us persistence and the ability to do other things and that is also a setting that can be changed.
So we have encountered customer environments where they have already, before we even get in they have configured their single sign on portal to require that reauthentication with the multifactor token.
Before the multifactor token a new multifactor token is added to the account. So that is something really important to note and something that you can abuse right away by default in most portals we do need to adhere to some opsec, some operational security when we’re doing that though to make sure we don’t alert the user or do anything else that’s going to get us caught.
So the first OPSEC tip here is do not remove or reset any existing multifactor tokens. Because if I remove, remove or exist or remove or reset any existing tokens then the next thing that’s going to happen is that user is going to call the help desk because they’re going to try and log in with their own account.
It’s not going to work. And they’re going to call the help desk and say my multifactor token is not working. Best case scenario, the help desk is going to remove an existing multifactor token, our multifactor token, and then they’re going to add back the, the user’s new multifactor token that they enroll for them.
Worst case scenario, they’re going to escalate this weird, occurrence to security and now it’s going to be, obvious that an attack is taking place. They’re going to investigate, they might revoke whatever other access we’ve managed to get, other things like that.
So we don’t want to remove or reset any existing tokens if we can help it. Number two is use either the Google Authenticator or totp. Those are the same thing but TOTP is kind of generic term time based one time password.
Use the Google Authenticator or TOTP MFA token, if that available, if that option is available to you. So reasons you would want to use that type of multifactor token as an attacker are that first no push notifications are generated whenever you log into the user’s account.
So there’s not any push notification coming to the user to tell them there was just now a login attempt on your account. Also no network traffic is generated between your mobile device where you set up the token and the environment that you are targeting.
So there’s not any like IP address, device model, anything like that getting disclosed to that environment that would make this appear suspicious. because the way the TOTP token works is there’s basically a secret key that is shared ahead of time.
It will be either a text string or a QR code. And then you scan that QR code with your phone and now you’ve got a random say six digit code that’s being generated every 30 seconds and that’s what you type in to do your multifactor authentication.
And the other nice thing about that is since it’s just a QR code, you can easily share it between multiple testers. So if one of you gets hit by a bus or something else, and is not available to test that day, other members of the team can continue on without you if you’ve gone ahead and shared that multifactor token with everybody on the team.
And then the number three opsec, tip here is for all other token types, if you can’t do the TOTP type, then connect your phone to a geolocated VPN or some other geolocated IP address that’s located in the region where the user would legitimately log in from before adding the multifactor token to your phone.
Because, if the user gets a notification, such as a push notification or something else that tells them a new device was added, that’s going to be super suspicious to see, on the other side of the country a new multifactor token was added to their account.
Also it could potentially trigger an impossible travel alert where the user has just logged in from, Washington state and now you as the attacker are logging in from Florida.
And that’s impossible for them to travel that distance in five seconds. So that’s an alert that can immediately get you caught, immediately get the account disabled, that kind of thing get you kicked out of the environment.
The other tip for all other token types is to avoid using push notifications if at all possible. most situations the push notifications push to all the devices on the account.
So every time you go to log in and you get a push notification to do the multifactor authentication, the victim will also receive the same push notification.
And that could alert them that something fishy is going on. It will especially alert them to something fishy is going on if they get many push notifications. So if you do have to send push notifications, minimize the number of sign sign ins that you’re doing, log into some, high value resource such as the VPN or whatever, and operate from that for as long as you possibly can until you sign into something else again so that you minimize the number of push notifications that they’re getting.
And then the last OPSEC tip for you here when adding a multi factor token is make sure you set the user’s default MFA method back to its original value after you add your MFA token.
So this is an example in the screenshot of doing this in Microsoft 365 where the user originally had the Microsoft Authenticator token down at the bottom.
I added the Authenticator app, which is that totp Google Authenticator app. And after doing so I want to click on this set default default sign in method link at the top and set that default sign in method back to the Microsoft Authenticator.
So that way the next time the user comes and logs into their account, they are seeing something they are familiar with and they’re not seeing something that they don’t know how to operate, that they’re going to have to click something else to get back to their usual token type, that kind of thing.
Because if they get interrupted in their usual process and they don’t know how to continue, that’s likely to result in a call to the help desk and either some kind of, help desk action that removes our multi factor token or potentially an investigation.
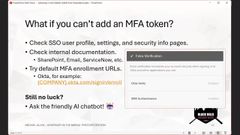
All right, so what do we do if we can’t add a multifactor token? This does happen. As I mentioned, some of our customers when we logged in had configured a more hardened configuration in their multifoldal and some of them had also configured it so users couldn’t add an additional multifactor token.
So the first thing that I do if I can’t add a multifactor token, if I get into a situation like the screenshot you see on the right where I see a list of the user’s tokens but I don’t have a button to add a new token to their account, the first thing I’m going to do is just browse through every page that is available to me that looks like it might be useful, like the user profile, the settings, the security info, all that stuff, and see if there’s somewhere else that a multifactor token can be added to the account.
Then I’ll go on to check internal documentation that I might find on SharePoint ServiceNow or in the user’s email and see if there’s any instructions in there. Maybe they have some other like additional web application or something else that’s used to manage their MFA tokens that I don’t know about that I might be able to gain access to.
And then the last thing to try here in the regular process would be, to try the Default MFA enrollment URLs if them. So I’ve got the Okta enrollment URL there as an example.
but if the URL, maybe it’s just been disabled in the web interface and maybe you can browse to it directly depending on the configuration that you’re up against. So if the URL, you can try going to it directly and maybe that’ll work.
But if none of that works really, interesting thing that happened, in one customer environment was there was a chatbot who was very friendly and helpful that I was able to interact with to get a multifactor token added to the user’s account.
So that’s what you see in this screenshot. Here is my conversation with that chatbot in teams that previous screenshot on the last slide was actually the same user account where I couldn’t add any multifactor tokens to the account.
When I got into teams, I saw they had Service Bot that I could talk to and ask questions about, it things in the environment. So I said, can I add an additional multifactor token to my account whenever I’m interacting with Service Bot here?
And Service Bot comes back and says, would you like me to reset your okta mfa? And I get three options there. Yes, reset mfa, no, and file ticket. Well, I don’t want to file a ticket because to me that sounds like that’s going to involve another human.
Someone’s going to review this. It’s probably not going to end well for me. So I went ahead and did yes, reset MFA and ServiceBot says, got it, working on it. And then comes back in the last message down at the bottom and says, click this link to set up your new multifactor authentication.
I did not have a link prior to that. I didn’t have a button in the interface or anything where I could go and add a multifactor token to the account. But Service Bot had access to do that for me and to generate this link.
And after Service Bot generated the link, I clicked the link and was able to add the multifactor token to the account no problem. But you might be wondering, you might be thinking like, didn’t you just say, we should not reset multifactor tokens ever?
That’s the number one rule. And doesn’t it say right here in the small text, clicking Reset MFA will reset all your configured factors, eg, sms, call push, et cetera.
yes, that is all true, but there is one exception. Whenever I think it’s okay to reset the user’s multifactor token and that is if they are out of the office. So in this particular instance I got really lucky when I logged into the user’s email.
I got a little pop up that said their automatic replies were turned on. So I went and checked the automatic replies and to see what the message said. And that’s the message you see in the lower left screenshot there, where it says I’m out of the office with limited access to email.
And this was on a Thursday. I, didn’t know, anything else about this user at that time. So I went and checked their calendar and did not see any kind of, time blocked off or anything like that telling me they’re going to be out of the Office for the next week or anything.
But then looking at their inbox and at their teams messages, I saw that they had a long list of emails and teams messages that had not been interacted with.
This was really funny because they had logged into our adversary in the middle phishing portal on this day. even though they were out of the office, they took the time to do that and make sure they got our $50Amazon gift card that we sent them for logging in.
But they weren’t logging in and checking their email or anything like that. So since this was on a Thursday, I thought, well, probably if they’re out of the office today, there’s a good chance they’re going to be out of the office tomorrow.
And I think we’ll have access until Monday. So I think between now and Monday we can probably leverage the access that we’ll get to set up other persistence to move to other resources in the environment.
And we’re not going to be interfering with anything that the user is doing today because they’re out of the office today. So this seemed like a viable, situation in which I might reset all of the tokens.
So in that case it did go very well for us. In most cases I would say don’t reset all the tokens yet. The out of office is the one exception to that. All right, so now number three, check for internal network access.
Hopefully at this point you’ve got a multifactor token added to the user’s account. So if you’ve got multifactor on the account that you control now you can log in anywhere you want.
So we got the username, we got the password, both of those from our adversary in the middle, phishing attack. And now we’ve got multifactor, so that, that’s all you need. but what if you did not successfully get multifactor added to the account, and you don’t control a token at this point?
Well, it turns out that you can use web based remote and virtual desktop access to get on the internal network through your web browser, just by having access to the single sign on portal session like we have with adversary in the middle fishing.
So on this slide I’ve got exactly the exact links that I click on every one of these after, I gain access to a user’s account. So that way I can see do I have access to any of these services, that give access to remote desktop sessions on say virtual machines or internal servers and workstations.
So I’ll go through a few details about each of these very quickly. but those links there are exactly the links that I recommend checking for. Most of this stuff, the Citrix VDI and the VMware Horizon, that VDI type of generic VDI access that you might have to do a little bit of digging for, say through SharePoint or through other documentation to figure out, where that’s located.
But otherwise all the other ones are just, links you can follow straight to get there. Okay, so this is the generic VDI type example in this case VMware Horizon.
And what I want to call out on this slide is in the left screenshot. When I get access to this account I’ve authenticated through single sign on, I, get the option to either launch the native client or to use the HTML access on the right.
And I choose that HTML access because if I launch the native client, I’m going to have to sign in to an application that’s running on my computer, which means I’ll be doing username M password multifactor authentication.
If I didn’t get that MFA token added to the account, I can’t do that. But because the VDI web application is using single sign on for authentication, I can click on HTML access and be logged right into the web interface.
And from the web interface then I can either get access to desktop instances, that’s the top section there, or to individual applications that have been shared through VDI at the bottom. If I get the desktop access at the top, obviously at that point I’ve got, full interactive desktop access.
If I get access to one of those applications at the bottom, I can just do a really simple shell escape to break out of the application and then get full desktop access to that workstation or server.
So this is, at that point I’m on the internal network. This works great for abusing that single sign on access. Similar for Microsoft 365 and Microsoft Virtual Desktop.
If you are signed into a Microsoft account for a user and you visit windows365.Microsoft.com you’ll see a page like the one in the top left here that lists your cloud PCs available to that user.
Or you’ll get a message that says the user doesn’t have any cloud PCs. If you see those cloud PCs once again, you want to click Open in browser. So that way you open the desktop session in the browser.
But first after you click that button, the next thing that’s going to appear is the in session settings that you See on the right. So, in those in session settings, I like to always uncheck printer, microphone, camera and location because I don’t want to share my location or my camera with the computer that I am, hacking right now.
But I do like to leave Enable, File Transfer and Clipboard because those are very convenient ways for me as an attacker to upload, C2 payloads or whatever to that machine that I’m getting on and to exfiltrate data out of the environment.
Very similar situation for the Microsoft Virtual Desktop that you see in the screenshot at the bottom. these are some examples of desktop apps that you would see deployed through the Microsoft 365 Apps page.
And every one of those again is an app that you could, I mean you can easily think of some shell escapes for every one of those applications, especially say Explorer and Notepad that would break you out into the, full desktop environment for whatever machine those are running on.
And then you can do whatever you want for your next actions after that. All right, so now we’ve got hopefully internal network access, but whether we do or not, the next step to do is to access in and persist in other web apps.
So the way we go about accessing those web apps first of all is to visit the Apps page or the single sign on Dashboard, whichever it happens to be called, where all of the applications that allow single sign on through our single sign on portal are listed.
So on the right at the top I’ve got a screenshot of the Okta Apps page, and at the bottom I’ve got the screenshot of the Microsoft Apps page. So just by clicking or double clicking, depending on the interface on each of those icons, then those applications would be launched in a new browser tab or browser window and you’d be automatically authenticated to that user’s account on that application.
So that’s really easy and straightforward way to get access to a whole bunch of other web applications on behalf of that user. And you never know what you’re going to find in those web applications.
In fact, in a couple of instances, the, applications we access through this method were where the crown jewels for the customers that we were targeting were located. We got access to things like VDI and stuff like that and got to the internal network.
But the data that they were really concerned about in some cases was actually in these web applications that you access this way. So it’s worth digging into every one of these. Another thing that I want to point out that is Absolutely worth doing every time is visiting that Microsoft apps page because even if they use Okta or some other single sign on platform for single sign on, sometimes Microsoft is still used for single sign on to some other applications or authentication to some other applications.
That can happen when either the organization used to use Microsoft as their single sign on platform and maybe they’ve transition to something else. But some of the third party applications that they use are still configured for the Microsoft authentication.
Or it can occur whenever say a third party service doesn’t support maybe Okta for single sign on but does support Microsoft. So they configure it with Microsoft because Okta is signing them into Microsoft and then therefore the user can access that application because they’re also signed into Microsoft at that time.
So always check that apps page on Microsoft 365 in addition to checking whatever the single sign on Dashboard is for the organization that you’re targeting. Now how do we persist in those web applications that we access through single sign on?
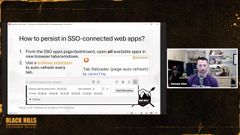
So we got access to them, we’ve got them all open in browser tabs. The next thing to do is get an extension similar to the one that I’ve got linked here. This is the tab reloader extension for Firefox.
I like to use Firefox when I’m hacking. So using a Firefox extension in this case link to that there on the slide and then there’s a screenshot of using it at the lower part of the slide and you can see like all you do is you click on this icon that appears in your toolbar and you get this little dialogue that pops up that asks how often you want to reload the current tab.
By default it’s set to five minutes. You can change that if you want to. You can change the variation, which is basically like the jitter, if you’re familiar with that term. And then click Start reloading. And that page is going to reload every five minutes or whatever you set it to.
What this does is it it simulates user activity on the page. So if you’ve ever say logged into your banking website and you left the page, unattended while you were, you got distracted, you were doing something else, maybe you were looking for a receipt, to match up to some kind of charge that was on there or whatever.
But because there was no interaction on the page, no one was clicking any links or anything, the page ends up timing out. It detects that Inactivity and it signs you out for security purposes.
Well we can prevent that from happening just by refreshing the page every so often. So the website thinks we are still interacting with the application. And the other thing that this takes advantage of is the fact that the web applications that use single sign on for authentication, their session timeout period is not at all connected to the session timeout period for the single sign on portal.
So I do this reload method on the single sign on portal and on all the web applications. But the single sign on portal, if it’s something like okta, it often has a fairly short session like hard session timeout that even if I’m reloading the page it still kicks me out after say 24 hours or something like that.
But even if I get kicked out of that single sign on session and I can’t get back in the other applications that I’ve opened in other tabs, I still have access to those because I’m already authenticated to them.
I already have a session cookie for those applications and as long as the session doesn’t time out in those applications, I can persist in them for a really long time. Some applications you can persist in for a year or longer.
And we’ve persisted in a lot of applications for like a very long amount of time beyond the end of the single sign on portal. Timing out.
One other thing that is important to mention here too before I go on to the next slide is this also applies to Microsoft services. So each individual Microsoft service also appears to have a different session timeout and session handling rules.
An example of that was we got access to a user’s Microsoft account and the blue team was onto us, they had detected some of our activity and so they were working on kicking us out of the environment.
I opened up the portal, the Azure admin portal in one tab and the Intune admin portal in another tab in addition to the Microsoft 365 tab that I already had open.
And I was active on all of those pages essentially refreshing them all, but I was actually manually active on all of them. Well the blue team was able to go ahead and kick us out of that user’s account.
They actually changed the user’s password and they killed the Microsoft 365 session. But even though they killed the Microsoft 365 session, my session in Intune and my session in the Azure portal were both still active.
So this was very interesting to us as attackers and absolutely something that you could take advantage of. So recommend opening each different Microsoft service and its own tab as well and persisting in those in the same way since their session, timeouts and other session behavior may not be, linked together directly or at the very least might not propagate over directly.
All right, and then finally we get to device code access to Microsoft services. So what is device code authentication? First of all, an example of this that you’re probably already familiar with, if you’re not, if you haven’t heard of device code authentication, but you probably use this is Netflix or other streaming services that you might open up on a smart tv.
So when you open up a streaming app on your smart tv, you probably see an image like what you see on this screenshot here where you get step one, you’re supposed to visit a URL or scan a QR code with another device like your phone or your laptop.
And then once you get to that URL, you are instructed to enter, the sign in code that shows on the screen, usually like a six to eight digit code, and then sign into your account.
So your Netflix account or whatever in that browser. Interesting thing, if you are already signed into your Netflix account, then when you visit that URL and you enter that code, you won’t have to sign in again.
What will happen is you’ll just get a quick prompt saying do you want to grant access to your tv? And you click allow and now your TV has access to your Netflix account. Well, for some reason that I still don’t yet understand, Microsoft also supports device code authentication and also, behaves the exact same way.
So I don’t know anybody out there that’s signing into their work, Microsoft resources from their smart tv. But this exists for some reason and we can abuse it.
So we use a tool called token tactics to kick off the device code authentication process. And then in the browser this is what that device code authentication process looks like.
So we get a device code or user code out of token tactics that we then put into a legitimate Microsoft website, as you see in the screenshot on the left.
and while we are logged into that user’s Microsoft, Microsoft 365 or other Microsoft resources. Once we click next, we then receive the prompt that you see on the right, the top right, asking, are you trying to sign into Microsoft Edge?
If we click Continue, then we get a response back that says you’ve, signed into the Microsoft Edge application on your device. You may now close this window. So we’ve completed the authentication process in the browser and now we’ve got a token in our Token Tactics or whatever other tool that we’ve decided to use for this that we can import into other hacking tools and now access Microsoft resources in the environment using those other hacking tools.
And we can do this even if Microsoft is not the single sign on provider that the organization uses. As long as that user has a Microsoft license and a Microsoft account in that company’s Microsoft tenant, we can take advantage of this.
So on this slide I’ve got a list of our go to tools for doing this type of attack and a few little notes here and there about each. Unfortunately I can’t go into the entire process of doing device code authentication and post exploitation in depth just because this is limited timeframe for this webcast today.
But I’ve got each of the ones that we go to immediately called out right here. So first is Token Tactics again to initiate that device code authentication and get the initial token and then also to refresh the token that we get to the other token types that are needed by other tools because every tool that we use is frequently going to use a different token type than other tools.
Then the next tool that we want to run with that token is Road Recon. I’ve got a link to that there and you can see the Road Tools logo up in the top right. So Road Recon pulls all kinds of information about the Azure environment of that Microsoft tenant, all the users groups, all sorts of stuff.
And what we found is that it gets us a lot of details about the users and other things in the environment that are not either included in the output of some other tools or not easily accessible in the output of other tools.
And that information has been very useful to us in things like social engineering attacks that occur later, where we might get say for example the employees ID badge numbers in some of that Road Recon output.
So that’s the first thing we run. It gets a bunch of information for us very quickly. The next tool that we go to is Graph Runner. And Graph Runner is basically a big suite of tools, all kinds of things that you can do through the Microsoft Graph API once you’ve got token access to an account.
I’ve got a few of my favorites listed here like adding a guest user accessing email accessing teams, stuff like that. But my absolute favorite in Graph Runner is the Snaffler like functionality that I’ve got linked on that slide and what it is basically, if you follow that link and you find snaffler like functionality on the page that it’s linking to.
On the Graph Runner wiki, there’s a code block there. If you copy and paste that code block into your Graph Runner session that you’ve got running in PowerShell, it will execute a series of commands that give you output like what you’re seeing on the right in the screenshot on the right side of the slide, where it searches through all the resources that are available to that user through SharePoint through OneDrive, and checks them for patterns in either the file name, the extension or the contents of the file that indicate that the file contains something that we as attackers are interested in, such as AWS keys, private keys, disk, images.
That was one that I found recently actually actually came from the same project as you’re seeing the screenshot where it says image, deployment on there. That was OVA files and VMDK files that I downloaded and some of those had credentials in them.
So there’s all kinds of very interesting stuff that you would find with Graph Runner and have access to and have the ability to do post exploitation actions that would not be so easy, say through the SharePoint web interface or other interfaces.
And then the last tool that I’ve got that I’ll call out here is Azure Hound, which is very similar to like if you use Bloodhound and used a Bloodhound Ingester in an Active Directory environment, very similar to Bloodhound, but it’s for Azure.
So you collect a large amount of information about the Azure environment and then you import that into your Bloodhound user interface. And now you can view different attack paths and privilege escalation opportunities and all sorts of other things, within Azure in your Bloodhound interface, just like you would for Active Directory.
Now I mentioned early on that the device code authentication requires a bit of caution and there are a few reasons for that that I’ve got listed here. So number one, we have to mind our opsec.
this is not necessarily obvious whenever you’re doing device code authentication. So I wanted to call it out. we should be using a geolocated IP address really for every action that we’re doing during post exploitation.
But make sure you’re doing that whenever you’re doing your device code authentication because whatever device generates the device code or the token is going to be that the IP address of that device is the one that will appear in logs and the one that will get alerted on.
Then number two is that detections exist for some queries and tools. in particular I’ve got a couple of blog posts here from Invictus IR linked that contain detections for Graph Runner.
The different actions that you can do with Graph Runner, things that indicate that someone is running Graph Runner in your environment. So we want to be mindful of those detections as attackers and also if you’re a defender, potentially incorporate those detections into your own environment.
And then number three is the detections exist for the device code authentication itself. a situation that we ran into very recently was like within the last couple of days actually was that a customer had configured the alerts in their environment in such a way that it was basically a honeypot for device code authentication where when we authenticated with device code authentication the account was automatically disabled and we lost access to that account, all access to the environment because this customer had identified that device code authentication was pretty much just an indicator of compromise because no one as I mentioned before, was using their smart TV to access their Microsoft 365 resources in that environment.
So that is also another trigger like just the device code authentication itself could be the thing that gets you caught. So we save this for last and use it with caution when we’re doing post exploitation and trying to stay covert.
There is an alternate option that you could do here where you could potentially obtain tokens from other Microsoft web apps rather than doing the device code authentication. But the problem with that is that they often have a greatly reduced scope that’s specific to that web app when we get them from web apps instead of from doing the device code authentication.
So not as ideal in that situation. But that is another way that you can go all right, so that pretty much wraps up the entirety of the the post exploitation triage process.
And I’ve basically just been talking about attack related things this entire time, things that are useful to us as attackers. So now that I’m in the conclusion, let me quickly circle back and give some key takeaways for defenders that want to defend against the stuff that I’ve been talking about today.
So the first key takeaway I want to give to defenders is to defend against that adversary in the middle attack. It’s specifically which is everything I’ve been talking about has been post exploitation.
We started with this talk with access to an account we’d already done a successful adversary in the Middle attack. If we had not been able to do that adversary in the middle attack we would have not been able to do anything else that I talked about today.
So to defend against adversary in the middle, there are two different ways to go about doing this that work very well. The first is to consider switching to an adversary in the middle resistant multifactor token for your users, such as one that’s U2F or Fido 2 compliant.
that will prevent current adversary in the middle tools from working. because of the way that that that standard of multifactor works, the, the authentication will not complete through the adversary in the middle portal and we will not be able to capture a session token number two, which is actually I think a bit more robust.
But just because it doesn’t, it’s not specific to the authentication is to consider allowing logins only from the internal network or the vpn.
So this would mean your users have to be either on the internal network like physically or connected to the VPN in order to log into any resources. And I’ve seen this happen especially say in banks where the tellers at the bank are only allowed to log in from within the bank.
They have no reason to really log into any work resources from home because they’re bank tellers and they’re not necessarily having to answer emails or something like that from home I assume.
So if you do that, the way the adversary in the middle attack works is that the login is occurring from our adversary in the middle server which is located on the Internet whenever the user logs into that portal.
So even if the user is logged into the VPN or on the internal network, if they try logging into our adversary in the middle portal and you only allow logins from the internal network or vpn, that login will still fail.
And that there is no way that I’m aware of to get around that. if you’re trying to log in externally unless you find some kind of gap in the deployment of that configuration or something.
But assuming it’s been deployed uniformly, not any good way to get around that. So those are the two first things to do as a defender.
Then if you want to defend against the post exploitation actions I talked about today, specifically the first thing you do is you want to harden the configuration around adding new multifactor tokens to the user’s account.
Ideally you want, if a user needs to add another multifactor token to their account, you want them to have to call the security team and have someone on the security team initiate adding a new multifactor token to the account, enrolling that token so that the user can do that.
not the help desk. We social engineer the help desk all the time. especially on the anti SOC team. So you don’t want them to call the help desk. You want this to be a thing for the security team to do.
Now if that doesn’t work for your organization, the next best suggestion is to require users to re authenticate with an existing multifactor token before they can add a second multifactor token to the account.
and that I have seen that configured in multiple single sign on portals. So I know that that configuration is supported by say Microsoft 365 and Okta for example. Then number two is to disallow device code authentication for all users by default and then add exceptions only when required.
I have yet to see an environment where device code authentication was actually required so this doesn’t seem to cause any kind of business impact where this is done. Again there is the option of using device code authentication as a honeypot but I think personally that it’s probably most secure to just disable it outright.
That will also prevent another attack called device code phishing which is another way that we get around multifactor authentication and get access to an environment. but like that way by disabling it completely you do just prevent everything that would possibly happen that’s bad related to device code.
And then finally the last two key takeaways, also specific to post exploitation are to configure the single sign on portal and all connected web applications to expire sessions in the shortest reasonable period for your organization.
Personally I recommend 12 hours as the max because that will give users a full workday plus extra time if they’re working late before they have to log in a second time.
And that way they only have to log in once a day to that single sign in portal and then they’ll have access to all the other applications as needed without logging in a second time. but the key here is to whatever, whatever period of time you land on to deploy that same configuration through all web applications that are connected to that single sign on portal.
So the user can’t persist in one, the attacker can’t persist in one after losing access to the other. And then number four, consider restricting remote network access to software clients only and disallowing access from the web browser.
That means for your VDI, for your Microsoft 365, anything like that. if you have the ability to lock down, access from the web browser, do so. Because when we have to, log in from a software client, instead of accessing the application for the web browser, we have to start a new authentication.
We have to log in with that multifactor token again. And if we don’t have the multifactor token, we can’t log in and do that. So, that prevents that type of access as well. And I’ll also point out that these last two recommendations, they also harden the environment against other attacks too, that are not adversary in the middle.
So an example being session tokens being stolen with info stealer malware. Somebody logs in to their work resources from a personal computer at home. And now that personal computer at home has a session token.
It’s stored in the browser in the cookie that has access to the environment. That person’s child downloads some game or something off the Internet. That game has malware in it.
That malware executes on the workstation, sends that session token off to the attackers on the Internet. Those attackers now trade or sell those session tokens to provide access to other attackers to the environment.
But if the session token expires before they have the opportunity to use it, now those attackers cannot access the environment even though they captured the session token, because the session token is no longer valid.
So, and same, goes for the software clients. The session token would be no good to a software client, only to a web browser. So, yeah, definitely recommend, those two key takeaways as well.
With that, I will stop here and, quit yapping again. if you want to learn more, I’ve got a link to my class there that you can take live or online. I’ve also got a link to the talk that I did in March of this year.
greetings from the red team. That is about, specifically about the postcard phishing attack that we did that led to all the massive success that, got us access through adversary in the middle, that I’ve been explaining today.
So if you’re interested in seeing how we got the initial access, that’s a good webcast to refer to at the moment. But with that, thanks everybody and, yeah, I’ll hand it back over to Jason.
Jason Blanchard
Michael, thank you so much for sharing your knowledge. I, like, as I’m listening to you, I can, like, I, I got a chance to talk with you recently about our Hackett program, and you’re like, well, couldn’t people do this?
Or this or this or this. Like, it always feels like your brain is like, how can I, how can I get around the rule that you’ve created? and so I, I love listening to you because I don’t know about any blue teamers here, but you’re like, oh, damn it.
Michael Allen
Like, yeah, that’s absolutely how my brain works. I’m always thinking, how can I get around whatever rule it is?
Jason Blanchard
Yeah. So, we’re going to stick around, we’re going to do some Q and A. And then if you would like to learn about what it, what it’s like to work with our continuous pen testing team, when the webcast is over in about seven minutes, you can stick around for that.
We don’t do any advertising during our webcast. We do. We wait for it after. and so if you want to find out what it’s like to be a customer or client. Client of the continuous pen testing, stick around.
When this is over, we’ll do about five or ten minutes of that with Corey and Michael and Brian. All right, so we have a bunch of questions here. so a lot of times people already get their questions answered while you’re talking.
So I just want to get people a chance. Like, if you didn’t get your question answered, please ask it again, either in zoom or in Discord. but here’s one. How can you harden it where you added another MFA while on their session, requiring MFA authentication?
Again, like, how, how can you harden it where you added another MFA while you were on their MFA session? That makes sense. Remember, like, because you were on there and then you added another mfa, but you didn’t have to re mfa.
Michael Allen
Yeah. So I, I think what they’re asking is, how, how would you prevent that? Right. Prevent adding that second mfa?
Jason Blanchard
Yeah.
Michael Allen
that configuration is going to be different for every different single sign on portal or, or multifactor, management portal, depending on what the case is. so I, I don’t honestly have the admin experience on that.
I’m actually like, kind of like Jason was alluding to talking about my mindset. I’m, pretty much 100% attack focused and not really, knowing as much as I probably should about the admin side.
A lot of this that I’m talking about today is coming from experience, just, doing the attacks. So I know that the configuration exists in there somewhere to, require additional, a second authentication before adding a multifactor.
Because I’ve seen it. I’ve been stopped by that. But I don’t know, specifically where in the Okta admin portal or where in the Microsoft admin portal those settings are.
Jason Blanchard
does U2F? I wish I knew what that meant. U2F or FIDO2MFA require hardware keys?
Michael Allen
I don’t believe that hardware keys are required. I think you can use like pass keys, as long as they are compliant with those standards. and it looks like. Corey, you got any extra information on that you want to jump in with?
Corey Ham
So it doesn’t. I mean it’s like, does it require hardware? Yes, but the hardware could be a laptop. Yeah, you could have a, basically like a, hardware version of a laptop instead of a key.
Michael Allen
So you basically have a soft token, right?
Corey Ham
Yeah, basically. Yeah, you can have a soft token for FIDO AH2 compliant. And there’s also difference between like universal two factor and FIDO 2. FIDO 2 is the broader standard that means like PASS keys and also MFA.
But U2F is specifically universal second factor is what that means. And it basically is cryptographically secure. MFA basically is the long and short of it.
Jason Blanchard
Yeah, question here. How do you deal with inbox rules if they get alerted on new policy creations?
Michael Allen
So I guess I suppose the question is like, what if creating the new rule in the email, what if that generates an alert?
hopefully that doesn’t happen with some of this. We are operating kind of blind and in the dark, so we have to just work off of our experience and what works like 90% of the time.
So it is possible that could generate an alert. Honestly, there’s several things that I’m doing in there that could generate alerts. But what we’re seeing in most environments is that those things are not generating alerts.
Like talking about the email rules. For example, something that I have frequently seen generate alerts regarding email rules is if I get into a user’s account and I want to have a method of persistence such as creating a rule that forwards all their email out to my email where I’m, I can read all their email even if I lose access to the environment that.
In most environments that’s going to get you kicked out, that’s going to get detected, they’re going to investigate, they’re going to kick you out. But creating an individual email rule that does not forward anything anywhere, it just deletes something.
I have yet to see that be generated, alert in any environment. And one reason I would suggest is probably the case for that is, I mean, users have got to be able to create that rule for legitimate purposes.
Like what if they’re getting a ton of junk mail or something, they don’t want to get that they’re going to create a rule to automatically delete it. So, anything that legitimate users are doing, for legitimate purposes is often something very good for us to do as attackers.
And that’s kind of a key concept. It’s actually one of the main key concepts that I talked about in the Red Team class is to use legitimate tools and legitimate business processes as much as possible as an attacker.
Because you’ll just blend in with everything.
Jason Blanchard
there might be a question that we’ll have to follow up with with a blog or something like that. It’s just, it says, have you, have you ever tested against this new control access policy against token theft? And it’s got a link to it. So, what I think might have you do is take a look at that link and then answer, the question somehow later on.
and there was a couple more questions about conditional access. my question, Michael, like, it’s a kind of a personal question. As a human being, who gets to do this kind of work?
When you find a new way in, how does that make you feel?
Michael Allen
Hmm, good. yeah. excited. it makes me feel smart. Makes me feel, all the good feelings.
Jason Blanchard
Yeah. And if you can find a way in, do you assume the defenders are really good at security or that you’re not as good as you thought you were at pen testing and initial access?
Michael Allen
not really either. I mean, if I can’t find a way in, then that, usually indicates it’s a hardened environment to current standards and current best practices and stuff.
But, something that I feel pretty strongly about is, there are vulnerabilities around us all the time in software and, security awareness, whatever it may be.
And when we hear about, some kind of new exploit coming out in the news or whatever, and it’s quickly being exploited by everyone. Well, that thing existed out there for a long time before some person found it and turned it into an exploit.
And then everyone started exploiting it. So, to me, my feeling is just, I just have to get more creative. I heard this, speech one time.
I forget the guy’s name that said it, but, he said, the brick walls are just there to keep everyone else out. And that’s exactly how I feel is they’re just there to keep everybody else out, not me.
Jason Blanchard
So that almost feels like a good way to wrap this up. But I always like to do. If you could wrap up today’s presentation, one final thought. What would it be?
Michael Allen
Oh God.
Jason Blanchard
Mhm.
Michael Allen
Don’t get caught. I guess.
Jason Blanchard
Okay, perfect. so we’re going to stick around for a couple minutes if you want to find out what it’s like to work with our continuous pen testing team, which we internally call the Anti Sock and sometimes externally called Anti Sock.
They have a Axolotl as their mascot. It’s fun. It’s a hacksolotl. Anyway, so what we’re going to do now is say thank you so much for joining us. If you got to go, we get it. We understand.
We’ll be back next week. Craig Vincent’s going to be here to talk about, finding vulnerabilities in desktop applications. So definitely check back with that. And then we have a summit coming up in December. You should check that out and then join us at Wildest Hacking Fest in Denver.
Bryan Strand
Okay.
Jason Blanchard
Okay. So that is the end of the webcast. If you’re sticking around at this point, you’re going to hear what we like to call promotional material. we’re not very good at this.
We probably suck at capitalism. We don’t even have a marketing team. we killed the marketing team back in 2019 like Ryan did it.
Corey Ham
Is that what the confrontation was about?
Jason Blanchard
Part of it? No. so if you are here and you do want to hear what it’s like to work with our continuous pen testing team, feel free to ask questions inside zoom of like if you want to know more about continuous pen testing, how it works, how to become a, to be a client, or how to request our services.
So we got Brian here. He would be on the business capture team. If you send an email to consulting at black hills infosec.com or if you go to the website and you go to the contact us form and fill that out, Brian’s going to be a part of that team.
And then we got Corey who leads the cpt, and then we got Michael as a part of the cpt. Is that right? I get that. Right.
Michael Allen
Yeah.
Jason Blanchard
All right. Okay. So, and someone just asked if we’re attending EK Echo party. we’re not. We had some people who were going to go down in Argentina, but unfortunately they won’t be able to go.
But we’re we’re sponsoring Echo Party for their hacker. Outreach program. Okay, so my first question is, when someone hires us to be continuous pen testing, is that for like six months?
A month? Like a year? Like what, what’s it for?
Corey Ham
Default is a year. we have some very trusting clients that signed up for like multiple years at once. But, in general, it’s a year.
there is a fun little thing because we’re Black Hills and we suck at capitalism, that, there’s no cancellation fees, there’s no minimum commitments. So if it comes, if a company comes in, says, all right, it’s been a month.
Rhino destroyed us, we want out. That’s always an option. But a year is the default.
Jason Blanchard
Okay, and why do you think a year is needed?
Corey Ham
It’s a good question. I think the biggest thing is just so we can fail more and learn more. That’s really where the basis of Anti Sock came from. Rhino and I were both legacy red teamers at Black Hills and have.
I’ve been red teaming almost exclusively for like five plus years now. and when you do a red team, at the end of it, whether it’s a month, two months or longer, you’re always like, I wish I had more time because I messed up that fish.
But I know now what I messed up and I could do it again and do it right. and so that’s a big factor is like just the ability for us to fail more and learn more.
the other big factor is we can wait for attacks, to become viable. right. So let’s say there’s a CVE that’s released.
There’s no poc. Maybe in a month there’s a poc. Maybe Spectrops just makes a blog post at the right time and now everyone gets DA again because they have some new ADCS vulnerability or whatever.
and also the info stealer angle. Like, you never know when that info stealer is going to be published. so if we’re around in the environment for a year, the chances that something that gets us initial access comes along just kind of drops into our lap is way higher.
So those are the big reasons. It, also gives our customers more time to fix things, or try things multiple times. Like, we’ve had some funny scenarios with customers where we found something, they fixed it, then a month later it came back and they’re like, dang it, it came back.
Are you serious? so we had to, report it again and fix it again. And hopefully the fix will take this time, but if not, we’re gonna report it again, so. Yeah, yeah.
Jason Blanchard
And, and how’s the reporting work? Are you like, you continuously writing pen test reports then?
Corey Ham
Basically, that’s kind of like the simplest way to look at it, but it’s all ticket based. So a ticket could be a full blown pen test report that has way too much information about, what PowerShell settings and themes Michael Allen uses.
or it might just be, a ticket that says, hey, we found this. we don’t really know what it is, but there’s a bunch of employee email addresses, so you should probably go close that or whatever.
So basically, yes, a bunch. And we call them micro reports or whatever. Like basically just having a bunch of small piecemeal things. It makes it easier to digest, for our clients to be like, okay, this is a series of tickets, right, Instead of like a 300 page report.
this is a small thing we can fix quickly. This is a long thing that’s going to take us a long time to fix. So they can kind of like piecemeal it a little bit more.
Jason Blanchard
Yeah. And, and Brian, you’re like a sales bro, right? Like when they reach out, you’re just going to hound them until you get your quota. Is that, that happens?
Bryan Strand
yeah, if I worked at another company. But I, I don’t. We don’t do quotas, we don’t do commissions. no. so, it’ll, it’d be, it’d be just like pen testing.
Honestly, it’s the exact same approach. Honestly, we actually, with bigger contracts like this and soc, we tend to know that it takes a lot longer to get through things. So by and large, it’s going to be the same process.
We get on a call with you, we send you a quote. You like the sound of it. Cool. If not, we’re not going to be pestering you or anything like that.
Michael Allen
No.
Jason Blanchard
Yeah.
Corey Ham
And wait, we don’t whine and dine and our clients, well, potentially maybe your golf game.
Bryan Strand
Hey, if you want to fly me out to where you’re at and do a round of golf with you, I’ll do that. Sure. Not going to be.
Corey Ham
I like to do that.
Jason Blanchard
That’s backwards. Like instead of. Anyway.
Bryan Strand
Oh, you want us to wine and dine them? Oh, yeah, yeah.
Corey Ham
Why would, why would a company wine and dine the sales team of a venture?
Bryan Strand
Hey, what? It has happened exactly once actually since I’ve started.
Corey Ham
So you really are, you not a sales bro?
Bryan Strand
No, no, I’m A sales.
Jason Blanchard
That was the clearest indication that Brian has no idea how Sales bro life exists at all.
Bryan Strand
Okay. I will say I even heard the term before.
Corey Ham
So one thing that really broke me, is that people told me that mountain biking is just the, like, millennial version of golf. They were like, this is what people do now.
And I was thinking about how I do ride bikes with John Strand. I was like, dang it, he got me. They’re right. It’s true.
Jason Blanchard
It’s true. Yeah.
Corey Ham
All right.
Jason Blanchard
Anyway, Michael, we talked about, like, a brick wall just keeps other people out. So when you sign on a new client, are they just like this new brick wall for you? And you’re like, okay, okay, okay.
Michael Allen
I mean, sort of, but more so the way we do things on, the Anti Sock team, and like, one of the things that adds a lot of value to it is like Corey was talking about, we have the opportunity to fail more.
Something else we have the opportunity to do is to do more R and D. So we can see an opportunity for an attack or a technique or something that doesn’t exist yet.
And we can really figure, that out, say, on one customer’s environment, depending, on who it seems like it’s going to be most likely to work against.
And then after figuring it out, we can immediately execute it at scale against all of our customers. So rather than with a traditional penetration test or traditional red team, where, for one thing, we have a much smaller period of time to try and figure out novel things to do, and it’s only running against one customer in cpt, all of the customers get the benefit of that R and D, and we’re able to dedicate more time to it, to do things much more similar to what a real world threat actor would do as far as building custom tools, which is required much, much more frequently these days than it has been in the past, and coming up with novel techniques or even just novel social engineering ruses and stuff like that.
Jason Blanchard
Yeah. A, question just came in from the audience. Does continuous pen testing count and make organization, compliant with the intent of PCI controls?
Corey Ham
Yes.
Michael Allen
Yeah.
Corey Ham
I mean, well, yeah. So basically, we will satisfy any kind of security testing requirement. We won’t actually do the PCI or FedRAMP or whatever checkbox you need to check.
That’s between you and whoever’s certifying you for that thing. and just to kind of like put an interesting thing in people’s ears. I personally believe in the next 10 years that regulations will require continuous pen testing.
Because a point in time pen test is not exactly the best picture of an organization. Right. If the goal of compliance is to confirm that an organization is doing due diligence, getting a week long test a year, one out of 52 weeks isn’t necessarily an indicator of that.
Having someone more tenacious and evaluating the environment on a continuous basis I think will be required in the next ten years. it actually has already been required for large financial organizations in Europe.
There is a requirement that it’s not just a point in time pen test, that it’s a continuous, subscription. So that’s just my personal take. Obviously I’m a little biased because that’s my whole entire business unit.
But, I do think like over time I could see regulations shifting to require like more than just one pen test a year, one week a year.
But who knows?
Jason Blanchard
So you got like Brian. So people reach out to, consulting at, Black Hills infosec.com to get this whole thing started. They talk to Brian or Tom or Logan. You guys aren’t on commissions.
You’re not here to make quotas. Like, you want to make sure that this actually makes sense, goes through the long process. And then what’s the onboarding look like?
Bryan Strand
Oh man. I’ll let Corey talk about the onboarding stuff.
Corey Ham
That’s pretty, I mean, yeah. So basically the first quarter of testing, once a client signs up first, we set up rules of engagement, what we’re allowed to do, what we’re not allowed to do. and that depends on the company.
Some we also set up goals and like, what is your objective? Like I ask every customer, in a year, why would you renew? Or why wouldn’t you renew? Like, what would be the reason why you’d keep this subscription or why you would cancel it?
so we get individualized goals for each customer, which does vary depending on what the industry is or the vertical or whatever. but yeah, the first quarter of testing, we call it baselining.
It’s basically external attack surface enumeration, scanning for any low hanging fruit. And then some basic social engineering attacks to try to gain initial access.
After that first quarter, that’s when we’ll start offering our customers like campaigns like, hey, do you want to do this campaign? Do you want to do that campaign? So it kind of like it ramps up. And then probably after about half a year, maybe three quarters of a year, we would get into like assumed compromise stuff.
So like get, having them if we haven’t gained access Having a customer deploy access for us or seed access in some way, whether it’s a valid account, a consultant, whatever it is, and then it kind of closes out after a year of like, hopefully at the end we would maybe do some purple teaming or something and have a little bit of collaboration, like hey, we built these detects, let’s make sure they work like that kind of stuff so well.
Bryan Strand
And for me a lot, a lot of that goes back to like why a year. and it’s like the story I like to tell people is I was reading this article when the MGM hack came out and I stopped reading it after this one line.
It was like a 10 minute phone call toppled a multi billion dollar organization. It’s like that’s so disingenuous. That’s not what happened. There was, there was hours of phone calls and hours of reverse engineering the call tree and their answers and all these different things.
There was so much time they got put into that and then it was a 10 minute phone call. And kind of the same philosophy can be applied towards like the CPT as well.
Corey Ham
Like.
Bryan Strand
Right. Are we going to be able to get like get in, get to Domain Admin, like own the whole environment in like two weeks? God, I hope not. but I doubt that’s going to happen.
Michael Allen
Right.
Bryan Strand
but, but those are probably not the types of customers that would want a cpt. Right. The ones that don’t have any kind of testing, don’t have any experience with security, anything like that. So. But that’s one reason why it’s like a year and there’s a good cyclical nature to it.
Corey Ham
Totally.
Jason Blanchard
I know you have someone on the team. I’m not going to call them out specifically, but you can if you want to, who is just absolutely a beast at social engineering calls.
So is that a part of the whole continuous pen testing, social engineering and initial access and like all the things. So tell me about the social engineering part.
Corey Ham
Sure. I mean you’re talking about Alice, who recently gave an awesome talk at Wild West Hack Infest, which isn’t public yet but hopefully will be posted at some point. so yeah, I mean basically with Antisoc we’re trying to emulate real threats.
We’re not, I have, this is going to get into like maybe some hot takes, but I like to ask the customers like when’s the last time a breach originated from a Cali implant in someone’s internal network?
I don’t think that’s ever happened to my knowledge. or when’s the last time a breach originated from of nessus finding? I mean maybe for the least secure organizations that’s possible, but we know real breaches happen from social engineering.
And so a significant portion of it is emulating social engineering. attacks the MGM thing that has led to Alice destroying help desks for an entire year.
And I would say her hit rate has got to be in like the 80% range or something. It’s insane. It’s way higher than your hit rate for any other, technique.
so like basically social engineering is just requirement these days. The other thing, almost every attack is going to require social engineering as a component.
It might not be the core part of the attack, but whether. Let’s say we compromise an account from password guessing. Well, they probably have mfa. So now we need to either social engineer the help desk or social engineer the user because we have to get past mfa.
So it’s like if it’s out of scope, I think it’s really hard to give a realistic perspective on a pen test, social engineering specifically.
But yeah, no, I was going to say that.
Bryan Strand
And that’s another good aspect of that. Going back to probably what kicked this whole thing off, at least from some of the. I came in probably halfway through most of the conversations for the CPT stuff. But like when you look at like a red team, right When I think Corey, when you first started, I think we are.
Our standard on our red teams was like two testers, three weeks, right? And we were doing two tester, two week red teams. And then we started to come up with these concepts of like, well, let’s do accelerators where they’ll do this for us and make this.
Make kind of cheat a little bit along the way and get us going. And it’s kind of like. And then we’d have people come to us like, well, what if I just don’t have you do like any social engineering at all and you come in and do like a two tester, two week red team.
Would that, would you be able to do that and see if you can get into the technical aspects of things? And it’s like at this point, why even call it a red team, right? what I mean? And kind of that same thing goes along with what Corey was just saying, right?
Corey Ham
We want to make sure like value, right? Like if you’re gonna, if you, if you’re gonna do that kind of like really short red team, I would just say, do you Want to assume compromise.
Bryan Strand
Right, Exactly.
Corey Ham
That’s it’s much more valuable. if you’re going to do a super, super long red team, I would say why not make it a year, right. Like just go anti sock. Right. So it’s like a lot of it is also sometimes when we’re trying to be stealthy, you can’t really compress stealth into a three week red team.
Like you just can’t because you can’t get into an environment and like hide because you, if you hide, you’re just wasting the client’s time. Right.
Bryan Strand
It’s hard to do it on a four week red team sometimes too. So.
Corey Ham
Yeah, yeah. I mean that’s another big point of it is like with anti sock we can test like dwell times, like long dwell times. if we, there’s a difference in the kind of severity that we report to our clients, we compromise an account and unit remediated it in three hours.
Okay, Maybe there’s some gaps there, but that’s a pretty good, time to close. If we’re in an account for like three months, we’re going to be reporting all kinds of findings.
Like, where’s your detects? Why aren’t you like what’s going on? Like why isn’t this happening? so yeah, like that and that’s time that the client.
We’re not just sitting there being like, man, I wish we could use the C2, but we know we’d get detected.
Michael Allen
Right.
Corey Ham
Like we’re going off and doing other things. So yeah, I mean it’s another kind of benefit of it is that we can actually do realistic dwell times that you would see in the real world.
Like obviously ransomware threat actors move really quick, but not every threat actor does. Right. We know espionage threat actors really like to exist and learn the environment slowly and live off the land as much as they can.
So we can kind of emulate that.
Jason Blanchard
So we’re doing this because we’re getting ready for 2025. And if you’re thinking about like potentially having this as a service, well, now’s the time to start thinking about it. and so if you want to reach out to us, go to blackhills infosec.com, go to our contacts page if you want to learn more.
We’re not great at like web design stuff. We’re not that great at marketing things. What we are good at is content and community and hacking and treating our clients really well.
And so if you go to our website and you’re like, I’ve seen better websites. Well, we have the best hackers. Okay. All right, so my last question is, if someone’s sitting here listening to all this and they’re like, well, am I the kind of organization that’s ready for this?
Like, who’s the kind of organization that’s ready for this kind of service?
Corey Ham
I mean, I would say the biggest thing, I don’t think the biggest thing I would ask our customers is do you have resources on your cybersecurity team to handle the amount of hacking that we’re about to, hand out?
Basically, are, do you have people who can read these reports and react and get involved with us and give us access? Or basically, do you have a security team that can engage with this?
If you’re a security team of two running security for a 10,000 person company, you probably don’t have time to interact with us. You probably have bigger fish to fry. But, if your security team of ten, maybe someone can be interacting with us and that while a real incident’s happening.
so basically that’s the biggest thing from my perspective is that the organization who signs up has the resources to actually benefit from the offering. Right.
Wade asked how many people? I think it depends on the company size. Right. I think honestly, as long as we have one point of contact that can consistently reply and can be engaged with us, then it works.
but are the customers who get the most value out of it have, 10 or more people in the, whether it’s the sock or whether it’s. You can add as many users as you want into the JIRA portal that we have and that basically gives you full visibility of like, maybe the soc doesn’t engage with tickets that aren’t, specifically hacking related.
Maybe they don’t engage with web app stuff. And then maybe you have the AppSec team who engages only with the web app stuff. So that’s the biggest thing is just that you have a security team that would, that could engage with us.
Right. We hate it when you just publish a bunch of pen test reports. They end up in SharePoint and no one ever reads them. That’s like the worst. the other thing is. Just go ahead.
Bryan Strand
No, I was going to ask you, what about companies who’ve like, never done much pen testing or never done much red teaming like this?
Corey Ham
Yeah, I mean, in that case I would always say, what is your worst day as a CISO or as like a high level executive? It’s probably, assume compromise would cover it, or even an external pen test would cover it.
I don’t think there’s anything wrong with being an immature organization and signing up for anti soc. You just have to be able to know that you’re gonna get destroyed.
Michael Allen
Right?
Corey Ham
Like you’re gonna. If you don’t have things like edr, mfa, all that good stuff, it’s going to be, a lot more findings for you. But if you’re okay with a lot of findings.
And we’re okay with it too, right? We have customers that have, I don’t know, 40 plus open findings at any given time. They can’t close all of them within 90 days, but they’re slowly working and after a couple of years, we’re seeing movement.
So, yeah, I mean, basically it’s just a matter of, having the staff and personnel to interact with us is the biggest thing. otherwise it, it’s not that we can’t do the testing, we’ll still do all the testing.
It’s just, it kind of, it leads to kind of a stalemate where it’s just like, we’re, we’re like, okay, well can we, can we do this fish? And then we get no response and so we just don’t do the fish.
that’s the biggest, negative for us is that we can’t do what we need to be able to do. But yeah, I mean, I would say it, it’s, it can work for almost anyone, I think.
Jason Blanchard
And I’m going to sound a little like a telethon, but we have callers standing by or phone operator standing by. we actually already got a request for someone to talk to us about cpt.
So, if you’re listening, we saw it. so someone’s going to reach out soon about it.
Bryan Strand
There’s another one. Oh, and another one.
Michael Allen
Yeah.
Bryan Strand
Slow down, slow down.
Jason Blanchard
So, thank you for listening. Thank you for being interested in CPT as a service. Corey, if you could sum up all this one. Michael, I have. You do the same thing. Brian, I’ll have you do the same thing.
So, Corey, if you could sum up everything, one final thought, what would it be?
Corey Ham
I’d say anti sock is your friendly neighborhood apt.
Jason Blanchard
All right, Michael Allen, final thought still.
Michael Allen
Said, don’t get caught.
Jason Blanchard
And Brian, don’t trust salesmen.
Bryan Strand
Oh, shoot. That’s it.
Jason Blanchard
All right, well, thank you for sticking around for this. we only do this every once in a while, because most likely. We’re always booked, up. We are booked up. we just. In case someone needs the service and we can provide the service, then we want to make sure that this.
Services exist. Every once in a while, people are like, you’re like a webcast in a backdoors and breaches company, right? And you’re like, yeah. We also do pen tests and CPT and SOC services and other things.
so in case you didn’t know this existed, we wanted you to know it existed. And thank you for your time today. And with that, with that, with that, with that, with that. Ryan, go ahead and kill it with fire.
Kill it, Ryan. Kill it.
Bryan Strand
Why are we still here? Why are we here?
Jason Blanchard
Corey Ham
he waits.
He doesn’t kill.