PyFunnels: Data Normalization for InfoSec Workflows
TJ Nicholls // *BHIS Guest Contributor

TL;DR
How many times have you had to parse the same output from a tool? Wouldn’t you like to get that time back?
There is a lot of overlap in the tools we use and the workflows we perform as information security professionals. Let’s not reinvent the wheel every time we need to extract data from a tool.
PyFunnels can act as a centralized and collaborative library. Enjoy the fruit of someone else’s labor. ? If the capability isn’t there, consider committing your Python3 code to the library in GitHub for future use. Below is a quick example to get started.
pip install pyfunnelsfrom PyFunnels import PyFunnels#Specify the output file for each tool in a dictionary.source_files = { "spiderfoot":"/path/to/file/spiderfoot.db", "nmap":"/path/to/file/nmap_results.xml", "TheHarvester":"/path/to/file/theharvester-tester.xml" }#Create a PyFunnels object.PyF = PyFunnels.Funnel(source_files)#Do something with itdomains = PyF.funnel_data("domains") for d in domains:pass#Your use case here.
Currently, supported tools and data points can be viewed with a method.
PyF = PyFunnels.Funnel() capabilities = PyF.get_capabilities() print(capabilities)
Starting the Project
As part of my Master of Science in Information Security Engineering (MSISE) from SANS, I recently began a new project. The project needed to address something in security that hasn’t been solved. I set a priority for myself that it would be a Python coding project because it is a skill set I needed to improve. While taking a SANS course pertaining to the CIS critical controls, I learned that a key success of implementing a security control is automating it. This way, the control lives on when you move on to new projects. It is a great way to scale security and something I’ve been trying to incorporate into my projects. With that in mind, I also wanted the project to help with automation.
So, what fits in this scope and has not been addressed? This was a challenging question for me to answer. I began by brainstorming tasks that I perform on a regular basis and processes that would make my life easier. I put some feelers out to colleagues and went back and forth with my advisor.
An early idea was to figure out how to normalize indicators from incidents or cases so that pertinent data could be integrated into tools and possibly shared. Through some Googling, I quickly came across security incident response platforms (SIRP’s) like theHive project. This was a win and a loss. Dang, someone already did it. Oh wow, that is really cool, someone already did it!
I then began contemplating a way to normalize the output of tools. I believe it is something we as information security professionals reinvent constantly in our own workflows. In other words, there is a lot of overlap in the tools we use. If you and I want to enumerate domains and subdomains for a net block, chances are we may use at least one of the same tools during that process. So my thought was, why redo the work of parsing the output when it is something that has been done a hundred times over. There is usually nothing particularly hard about parsing output, especially if you use just one tool. But we have better things to do with our day, and the task starts taking more time if you use multiple tools to increase the fidelity of your findings.
PyFunnels
Enter Pyfunnels. PyFunnels is a Python3 library designed to aggregate data from tools and return a unified dataset. Even though the output from tools may not be standard, we can build reliable ways to retrieve the data.
Consider that we have one or more tools used to collect data. Tools typically have output that consists of multiple data points. When I say ‘data points’, I am simply referring to things like IP addresses, URLs, domain names, emails, files, login pages, etc.
The idea is to isolate those data points. The way you do that for each tool will be different, but we need a unified way to get a data point from each output. That is really the core of PyFunnels, create and store code to isolate data. The isolated data is then de-duplicated and aggregated. That aggregate data can then be leveraged for whatever the use case may be.
Here is an animated view of what I just described:
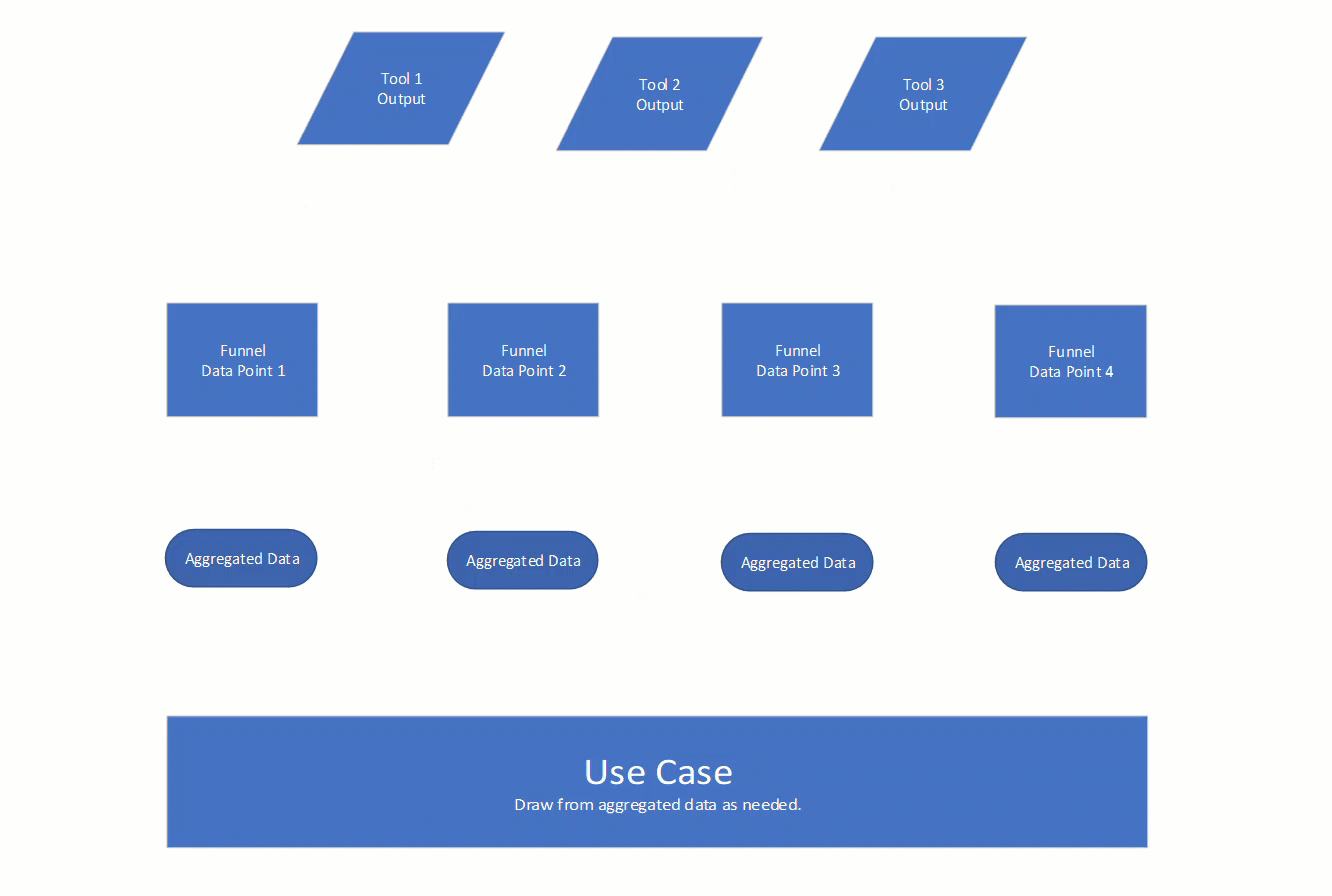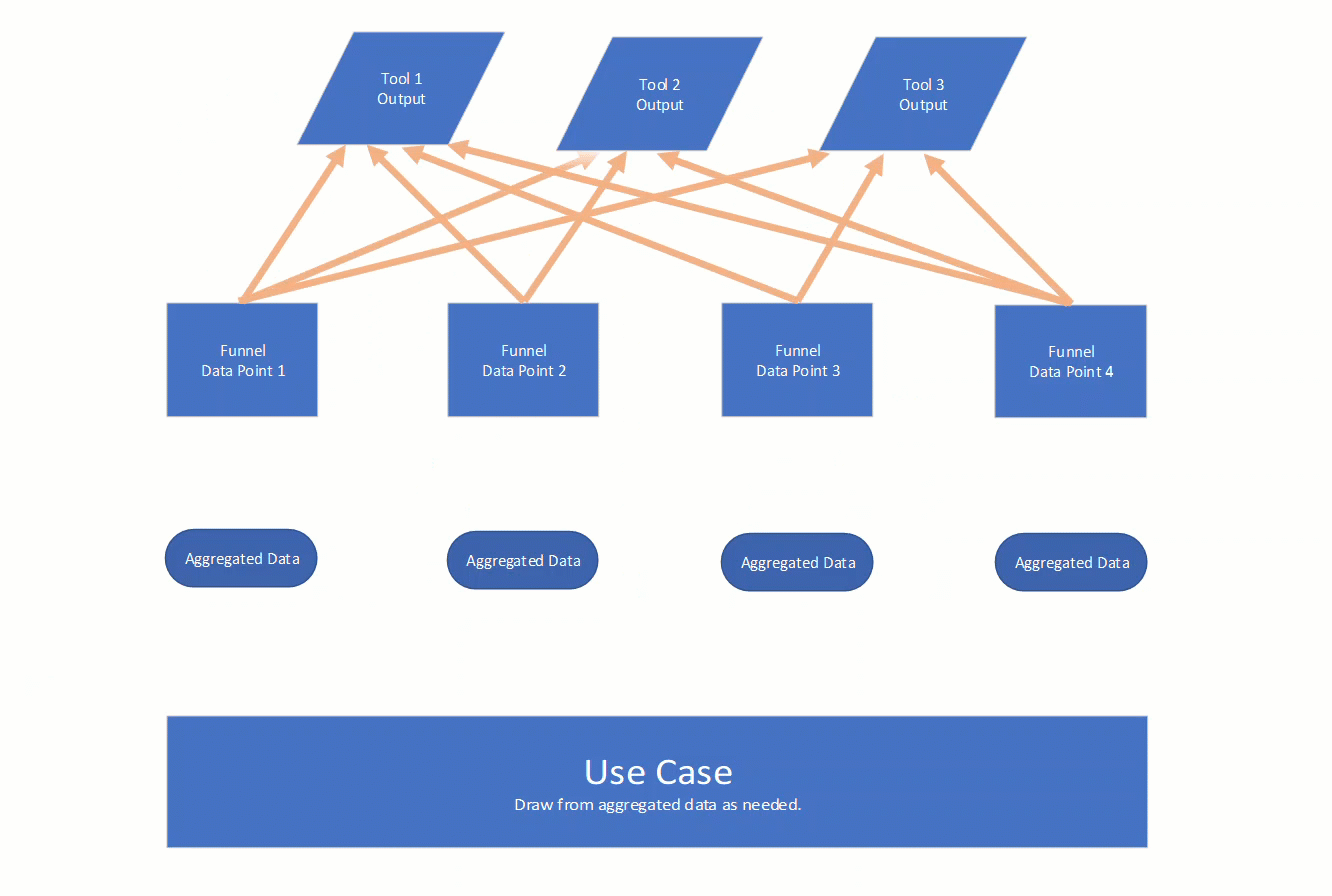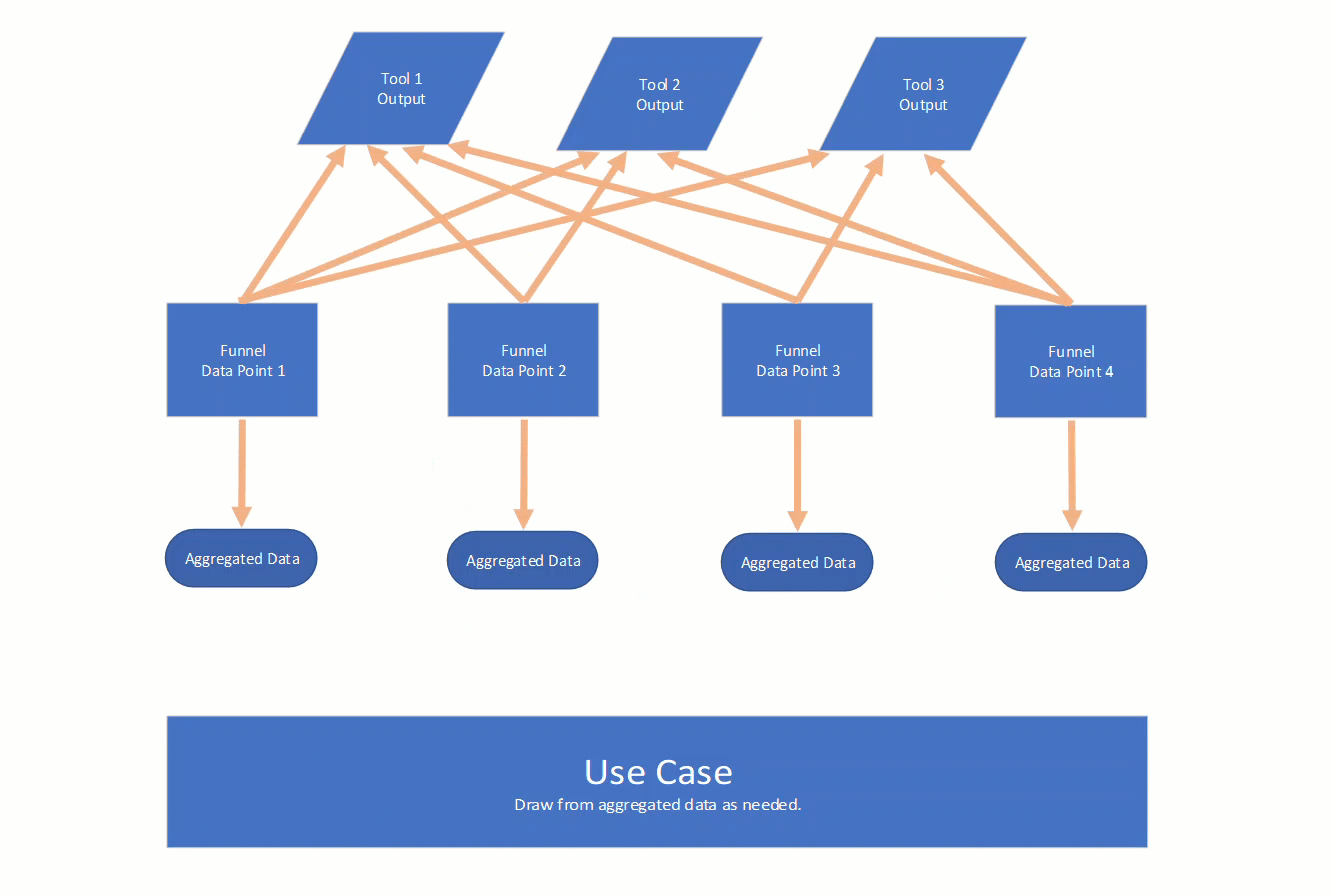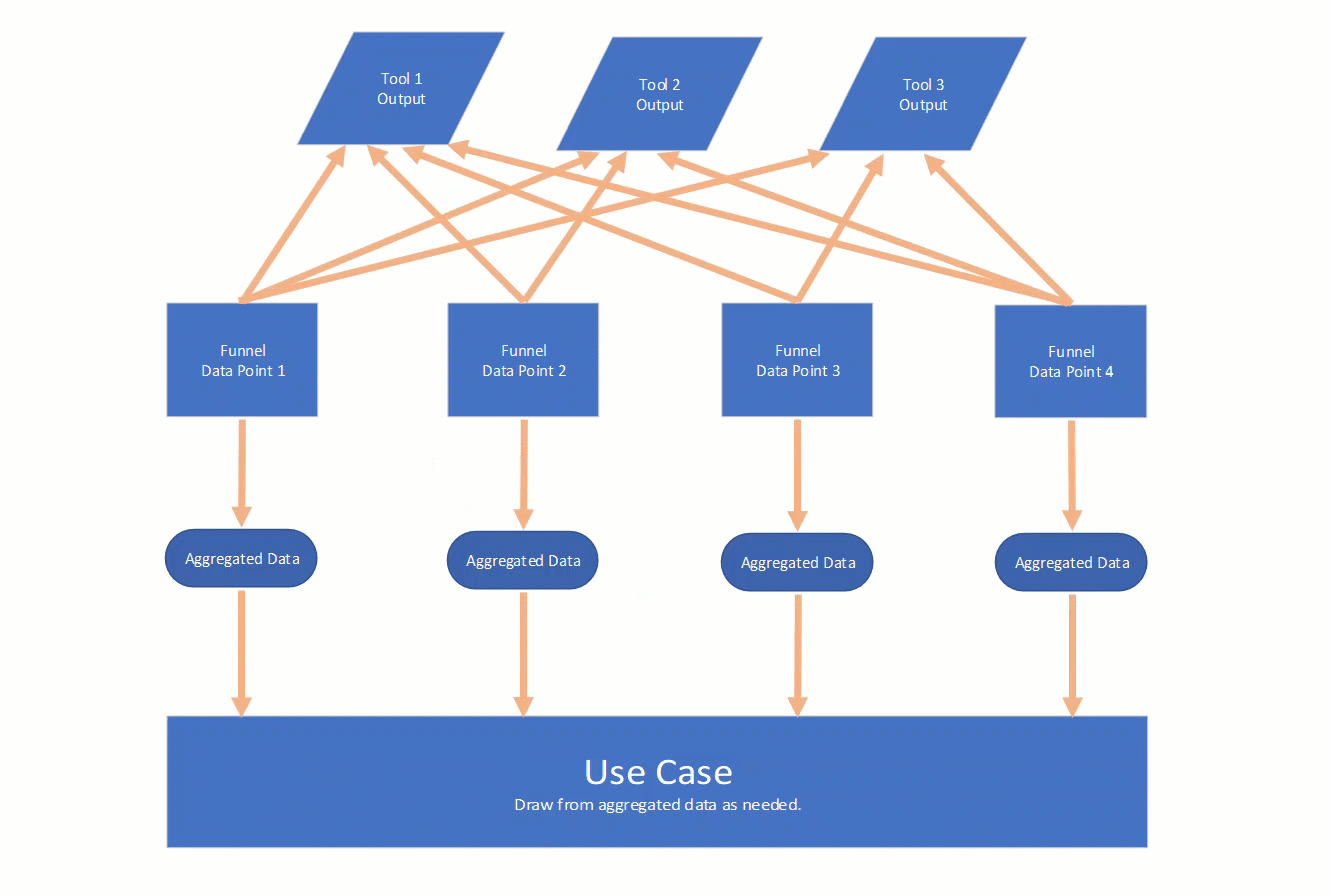
Example Scenario
Take an example of collecting domains and subdomains using five tools (overkill I know). The goal is to use the output to compare discovered domains against a known inventory. Once we have that information we can move on to remediation as necessary, decommissioning unapproved services or adding the appropriate protections to them. Ideally, this is an ongoing and automated process and an alert is generated when there is a finding.
PyFunnels’ goal is to expedite the process of extracting the data. Here is the process:
- Specify the output files (Figure 1)
- Instantiate an object (Figure 1)
- Call a method on the object, providing the data point of interest (Figure 2)
from PyFunnels import PyFunnels#Specify the output file for each tool in a dictionary.source_files = { "spiderfoot":"/path/to/file/spiderfoot.db", "recon_ng":"/path/to/file/recon-ng-tester.db", "TheHarvester":"/path/to/file/theharvester-tester.xml", "photon":"/path/to/directory/photon_results/", "nmap":"/path/to/file/nmap_results.xml" }#Create a PyFunnels object.PyF = PyFunnels.Funnel(source_files)
Figure 1: Example Setup
PyFunnels will return the de-duplicated and aggregated data as a list (Figure 2).
domains = PyF.funnel_data("domains") print(domains) Output: ['example.com', 'partner.com', 'related.com']ford in domains:pass#Your use case here.
Figure 2: Example Output
That is it. . .
Move on with your day. . .
Put the data to work. . .
You don’t need to reinvent the wheel. After all, you are likely not the first person to parse this data out of this output file. Save time with PyFunnels and use the code you or someone else has previously committed.
Thought Process & Lessons Learned
The design of PyFunnels is modular, where each tool is its own class and each data point is a method of that class. The tool classes work independently of one another. You don’t have to build all the methods for a tool. Ideally, every tool would have support for every data point it collects, but that can happen organically. Laying out the library this way makes it easy to contribute for any level of programmer and allows PyFunnels to accommodate an unforeseen amount of tools.
This has been my first real coding project. After I settled on the idea, I just started running with it. An early problem I encountered was I found myself reusing chunks of code while calling each tool. I didn’t know the best way to layout the classes and methods. After a peer review and some research, I was able to condense 147 lines of code to 12 lines. This was a huge moment for me and necessary for the library to grow. My lesson learned here is that if you have an idea, start putting it together. The code may not look great at first but you can refine and make improvements as it develops.
Conclusion
Information security is a unique field where we do not need to compete with each other. Across industries, within the same industry, it is in our best interest not to compete. That was a big motivation for this project, I wanted to find a way to collaborate and provide value to the community.
I believe this can become really powerful with some community adoption. The concept for PyFunnels can be simplified to, as you write Python3 code to isolate data from a tool, commit the code so it can be reused.
My goal is for PyFunnels to be something useful for other professionals and for it to grow to support a large range of tools and data points. If you use the library and/or take a look at the code, I’d love feedback. Coding is new to me and I’m sure my implementation can be improved.
Thanks for reading, I hope you find the library useful and are able to use it in your workflows.
The PyFunnels library can be found at:
https://github.com/packetvitality/PyFunnels
https://pypi.org/project/PyFunnels/
The full paper I wrote as part of my MSISE can be found at:
*Note: I’ve packaged the library and made modifications since I wrote the paper. Refer to Github and documentation within the library for current usage examples*
Ready to learn more?
Level up your skills with affordable classes from Antisyphon!
Available live/virtual and on-demand
